Python Pandasを使ってExcel読み込みと書き込み

業務でExcelを利用していますか?もしPythonでExcelと連携を行い、プログラムを利用して操作できれば業務の効率が上がること間違いなしです。PythonはWindowsでも簡単に利用することができるプログラム言語なので普段利用しているパソコンでもすぐに実行することができます。
本文書ではPythonのデータ解析のライブラリであるpandasを利用してExcelの読み込み方法を確認していきます。ExcelはCSVファイルとは異なり複数のシートを含めることが可能なので複数のシートがあるExcelファイルからのデータの取得方法についても説明しています。Excelからデータ取得後の処理についてはExcelから取得した後にどのように加工するのか各自の業務やアプリケーションに依存するのでデータ取得後のデータの処理方法については本文書では解説を行っていません。
実際の業務では取引先から送られてきた請求の詳細内容をEXCELから取り出し、業務アプリケーションのフォーマットに合わせて変換を加えてCSVとして業務アプリケーションに取り込むといったことに利用しています。
pandasを利用しなくてもopenpyxlライブラリを利用することでEXCELを操作することができます。
目次
Pandasのインストール
使用しているPythonの環境にPandasがインストールされているか確認を行い、インストールされていない場合にインストールを行います。
インストールされているパッケージの一覧表示にはpip list、個別のパッケージを確認する場合はpip showコマンドを利用します。
pip listを実行してpandasのパッケージが表示されなければ、pip install pandasコマンドでインストールを行います。
$ pip install pandas
Collecting pandas
Downloading pandas-2.1.4-cp312-cp312-win_amd64.whl.metadata (18 kB)
Collecting numpy<2,>=1.26.0 (from pandas)
Downloading numpy-1.26.2-cp312-cp312-win_amd64.whl.metadata (61 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 61.2/61.2 kB 542.2 kB/s eta 0:00:00
Collecting python-dateutil>=2.8.2 (from pandas)
Downloading python_dateutil-2.8.2-py2.py3-none-any.whl (247 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 247.7/247.7 kB 3.0 MB/s eta 0:00:00
Collecting pytz>=2020.1 (from pandas)
Downloading pytz-2023.3.post1-py2.py3-none-any.whl.metadata (22 kB)
Collecting tzdata>=2022.1 (from pandas)
Downloading tzdata-2023.3-py2.py3-none-any.whl (341 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 341.8/341.8 kB 7.1 MB/s eta 0:00:00
Collecting six>=1.5 (from python-dateutil>=2.8.2->pandas)
Downloading six-1.16.0-py2.py3-none-any.whl (11 kB)
Downloading pandas-2.1.4-cp312-cp312-win_amd64.whl (10.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 10.5/10.5 MB 10.2 MB/s eta 0:00:00
Downloading numpy-1.26.2-cp312-cp312-win_amd64.whl (15.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 15.5/15.5 MB 8.6 MB/s eta 0:00:00
Downloading pytz-2023.3.post1-py2.py3-none-any.whl (502 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 502.5/502.5 kB 6.3 MB/s eta 0:00:00
Installing collected packages: pytz, tzdata, six, numpy, python-dateutil, pandas
Successfully installed numpy-1.26.2 pandas-2.1.4 python-dateutil-2.8.2 pytz-2023.3.post1 six-1.16.0 tzdata-2023.3
pandasをインストールすると一緒にpytz, six, python-dateutil, numpy, tzdataもインストールされます。
% pip list
Package Version
--------------- ------------
numpy 1.26.2
pandas 2.1.4
pip 23.3.1
python-dateutil 2.8.2
pytz 2023.3.post1
six 1.16.0
tzdata 2023.3
・
・
また、EXCELの拡張子であるxlsのExcelファイルを読み込むためには、xlrdパッケージもインストールする必要があります。
$ pip install xlrd

Excelファイルの読み込み
Excelファイルを読み込むために pandasのread_excelメソッドを使用します。ここではsales.xlsxというファイルの読み込みを行います。日付と販売数を列をもつデータを持っています。
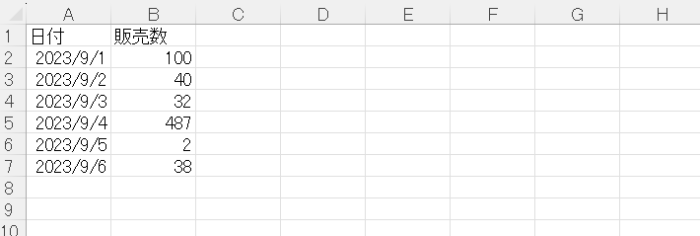
拡張子がxlsの場合にはエラーが発生します。
text.pyファイルを作成します。
import pandas as pd
df = pd.read_excel('sales.xlsx')
print(df)
実行するとEXCELファイルから読み込まれたデータを表示することができます。
$ python test.py
日付 販売数
0 2023-09-01 100
1 2023-09-02 40
2 2023-09-03 32
3 2023-09-04 487
4 2023-09-05 2
5 2023-09-06 38
実行して下記のエラーメッセージが出た場合はopenpyxlのインストールが必要です。
ImportError: Missing optional dependency 'openpyxl'. Use pip or conda to install openpyxl.
その場合は”pip install openpyxl”を実行してください。
$ pip install openpyxl
Excelファイルを開いたままpythonプログラムを実行して”Permission Error”が出て読み込みができない場合はExcelファイルを閉じて実行してください。
EXCELファイルを読み込んだ際のデータの型も確認しておきます。
import pandas as pd
df = pd.read_excel('sales.xlsx')
print(type(df))
実行するとDataFrameであることがわかります。
$ python test.py
<class 'pandas.core.frame.DataFrame'>
Excelファイルのシート読み込み
Excelファイルの中に複数シートがある場合は、すべてを読み込むことも指定したシートのみ読み込むことも可能です。
複数のシートがあってもシート読み込みオプションsheet_nameを指定しなければ最初のシートしか読み込まれません。
シートの読み込み設定には、sheet_nameオプションを使います。
すべてのシートを読み込む
sheet_nameをNoneに設定するとすべてのシートを読み込むことができます。
import pandas as pd
df = pd.read_excel('sales.xlsx',sheet_name =None)
print(df)
今回使用したEXCELファイルには3つのシートがあるためEXCELファイルを読み込むと下記のように表示されます。
$ python test.py
{'Sheet': 日付 販売数
0 2023-09-01 100
1 2023-09-02 40
2 2023-09-03 32
3 2023-09-04 487
4 2023-09-05 2
5 2023-09-06 38, 'Sheet1': 日付 販売数
0 2022-09-01 50
1 2022-09-02 58
2 2022-09-03 380
3 2022-09-04 50
4 2022-09-05 5
5 2022-09-06 12, 'Sheet2': 日付 販売数
0 2021-09-01 5
1 2021-09-02 100
2 2021-09-03 49
3 2021-09-04 39
4 2021-09-05 62
5 2021-09-06 92}
複数のシートから読み出した時の型も確認しておきます。
import pandas as pd
df = pd.read_excel('sales.xlsx',sheet_name =None)
print(type(df))
実行するとdictであることがわかります。
% python test.py
<class 'dict'>
シート名を指定して読み込む
sheet_nameオプションにシート名を指定することで指定したシートのみ読み込むことができます。今回はsheet1とsheet3を読み込みます。
df = pd.read_excel('sales.xlsx',sheet_name =['Sheet','Sheet2'])
実行するとSheet1, Sheet3のシートを読み込むことができます。
$ python test.py
{'Sheet': 日付 販売数
0 2023-09-01 100
1 2023-09-02 40
2 2023-09-03 32
3 2023-09-04 487
4 2023-09-05 2
5 2023-09-06 38, 'Sheet2': 日付 販売数
0 2021-09-01 5
1 2021-09-02 100
2 2021-09-03 49
3 2021-09-04 39
4 2021-09-05 62
5 2021-09-06 92}
シート番号を指定して読み込む
sheet_nameオプションにシート番号を指定する場合は最初のシートが0になるので注意が必要です。今回は2番目のシートのみ取得します。
複数の場合は配列で指定していましたが、1つの場合はシートの番号だけ指定するだけで大丈夫です。
df = pd.read_excel('sales.xlsx',sheet_name =1)
実行するとSheet2を読み込むことができます。
$ python test.py
日付 販売数
0 2022-09-01 50
1 2022-09-02 58
2 2022-09-03 380
3 2022-09-04 50
4 2022-09-05 5
5 2022-09-06 12
シート名とシート番号を別々に説明していましたが、これらが混在していても問題はありません。
また、読み込む順番を変えることもできます。
df = pd.read_excel('sales.xlsx',sheet_name =[1,'Sheet'])
下記のように読み込んだシートは表示されます。
$ python test.py
{1: 日付 販売数
0 2022-09-01 50
1 2022-09-02 58
2 2022-09-03 380
3 2022-09-04 50
4 2022-09-05 5
5 2022-09-06 12, 'Sheet': 日付 販売数
0 2023-09-01 100
1 2023-09-02 40
2 2023-09-03 32
3 2023-09-04 487
4 2023-09-05 2
5 2023-09-06 38}
dfから個別に取り出す
複数のシートを取り出した時、それぞれのシートのデータはdictの中に入っています。シート別にdictから取り出した場合はforを使って下記のように行います。
import pandas as pd
df = pd.read_excel('sales.xlsx',sheet_name =[1,'Sheet1'])
for key in df:
print(df[key])
$ python test.py
日付 販売数
0 2018-09-01 50
1 2018-09-02 58
2 2018-09-03 380
3 2018-09-04 30
4 2018-09-05 5
5 2018-09-06 12
日付 販売数
0 2019-09-01 100
1 2019-09-02 40
2 2019-09-03 32
3 2019-09-04 487
4 2019-09-05 2
5 2019-09-06 38
dfにキーを指定すると指定したキーのシートのデータのみ表示させることができます。
import pandas as pd
df = pd.read_excel('sales.xlsx',sheet_name =['Sheet','Sheet1'])
print(df['Sheet'])
$ python test.py
日付 販売数
0 2023-09-01 100
1 2023-09-02 40
2 2023-09-03 32
3 2023-09-04 487
4 2023-09-05 2
5 2023-09-06 38
読み込んだシートの情報を1行毎取り出す
読み込んだデータを1行ずつ取得したい場合はdf.valuesを使って取り出すことができます。df.valuesにfor文でloopすることで1行ごとにデータを取り出すことができます。print関数にf”で”の中に{}で変数を指定することで文字列として展開することができます。
import pandas as pd
df = pd.read_excel('sales.xlsx')
for row in df.values:
print(f'{row[0]}と{row[1]}')
print(row[0],"と",row[1]) //こちらで可
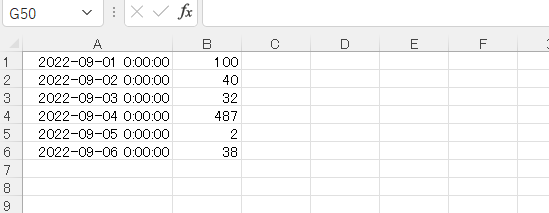
利用したEXCELファイルの中身は下記の通りです。
実行すると下記のように表示されます。
$ python test.py
2023-09-01 00:00:00 と 100
2023-09-02 00:00:00 と 40
2023-09-03 00:00:00 と 32
2023-09-04 00:00:00 と 487
2023-09-05 00:00:00 と 2
2023-09-06 00:00:00 と 38
EXCELファイルに複数のシートが存在し、シート名がSheet1からデータを取得したい場合は以下のように1行毎のデータを取得することができます。
import pandas as pd
df = pd.read_excel('sales.xlsx',sheet_name=['Sheet1'])
for row in df['Sheet1'].values:
print(f'{row[0]}と{row[1]}')
$ python test.py
2022-09-01 00:00:00と50
2022-09-02 00:00:00と58
2022-09-03 00:00:00と380
2022-09-04 00:00:00と50
2022-09-05 00:00:00と5
2022-09-06 00:00:00と12
EXCELのファイルからシート毎の行データを1つ1つ取得することができたので取得したデータを加工してさまざまな用途に利用することも可能です。
EXCELファイルへの書き込み
EXCELファイルから取り出したデータをそのままファイルに書き出したい場合は下記のように行うことができます。通常は取り出したデータを加工して新たにファイルに保存することになります。
実行するとtest.xlsxファイルが作成されます。
import pandas as pd
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
df = pd.read_excel('sales.xlsx')
for row in df.values:
ws.append([row[0],row[1]])
wb.save('test.xlsx')
EXCELから読み込んだデータを別のEXCELファイルへ書き込みを行いましたが通常は読み込んだデータに加工を加えて、新たにファイルに書き込むことになります。
pandasを利用したファイルの読み込み、書き込み方法を理解することができました。
