【完全ガイド】Python PDFから表を取り出しEXCELに保存する方法

PDFからデータ抽出でこんな悩みはありませんか?
- PDFに表データが含まれているが、うまくデータを取り出せないため、毎回手動でExcelに入力している。
- クラウドサービスでデータをPDF形式では無料ダウンロードできるが、CSVファイルでのダウンロードには追加料金がかかる。
手作業でのデータ入力は時間も労力もかかり、ミスも発生しやすいものです。そんな時に役立つのが、Pythonのライブラリを使ったデータ抽出です。
Pythonには、PDFから表データを効率的に取り出せるライブラリがいくつか存在します。例えばこれから紹介するtabula-pyやcamelon、pypdf、pdfplumberを活用することで、PDF内の表を自動で読み取りExcel形式(.xlsx)に保存することが可能です。
プログラムで実装できると作業時間を大幅に短縮するだけではなく手入力によるミスを防止することもでき安心して業務を行うことができます。

動作はWindows PCで行なっていますがmacOSでも利用可能なライブラリです。JavaやGhostScriptなどのインストール方法はOSによって異なるので注意が必要です。
目次
Pythonで利用できるライブラリ
PythonにはPDFのファイルからテキスト文字を取り出すライブラリが複数存在するのでどれを利用するのか悩むものです。PDFのファイルに含まれるテキストをすべてを抽出するものから表の抽出するものまでさまざまあります。またPythonのみでは動作せず、JavaやGhostScriptをOSに追加インストールしないと利用できないものもあります。本記事では4つのライブラリを利用してPDFファイルに含まれる表形式のデータが期待通りに抽出できるか確認していきます。
pypdfの利用した場合
pypdfは結合、分割などのPDFを操作する際に活用できる汎用的なライブラリです。
pypdfにもPDFファイルからテキストを抽出することができるのでpypdfを利用してPDFファイル内のテキストを取得してみましょう。
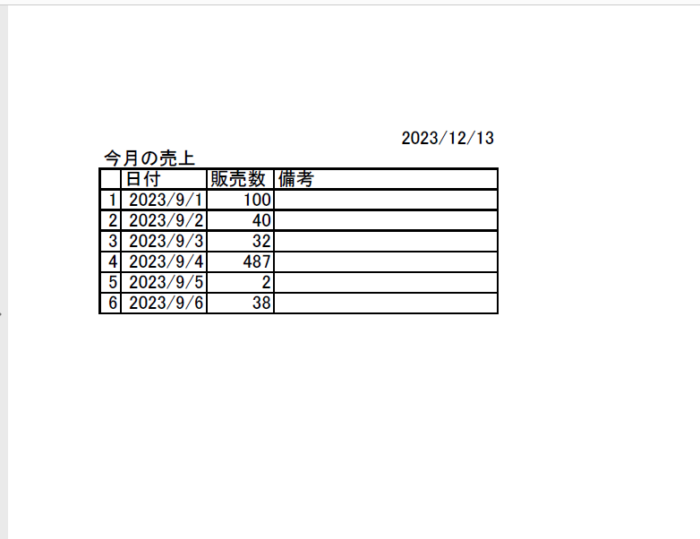
利用するPDFは下記のものでEXCELから作成したものです。ファイル名はsales.pdfとしてPythonコードを記述するファイルと同じディレクトリに保存します。
pypdfはpipを利用してインストールを行います。
% pip install pypdf
Collecting pypdf
Downloading pypdf-3.17.2-py3-none-any.whl.metadata (7.5 kB)
Downloading pypdf-3.17.2-py3-none-any.whl (277 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 277.9/277.9 kB 2.1 MB/s eta 0:00:00
Installing collected packages: pypdf
Successfully installed pypdf-3.17.2
pip listでインストールしたpypdfのバージョンを確認することができます。
% pip list
Package Version
--------------- ------------
pypdf 3.17.2
・
・
任意のディレクトリにtest.pyファイルを作成して以下のコードを記述します。これでコードは完了です。
from pypdf import PdfReader
reader = PdfReader("sales.pdf")
page = reader.pages[0]
print(page.extract_text())
作成したtest.pyファイルを実行するとPDFファイルに記述されていた内容がそのままターミナルに表示されます。
python test.py
2023/12/13
今月の売上
日付 販売数備考
12023/9/1 100
22023/9/2 40
32023/9/3 32
42023/9/4 487
52023/9/5 2
62023/9/6 38
テキストがそのまま表示されるのでデータ間の区切りがないためそのままEXCELに保存してもテーブルとして表示させることができません。
今回は比較的綺麗に上から順番にテキストを取得することができましたがPDFによっては行毎に取得できなかったりするのでpypdfではうまく処理を行うことができません。無理やり空白を見つけてそこに区切り文字をつけることがPythonでできないことはないですがおすすめできません。
pypdfでは表のデータをうまく取得できないことがありますが表ではなく文字列で構成されたPDFファイルから文字列のみ取得する際には活用することができます。また他のライブラリを利用した場合に依存関係としてpypdfがインストールされるということもあります。
tabulaを利用した場合
本記事の本題であるPDFの内部にある表を取得することに特化したライブラリtabulaを利用して動作確認を行います。tabulaを利用するために手元にPCやサーバ上で利用する場合にJavaをインストールする必要があるのでJavaを追加したくない場合やできない場合には利用することができないので注意が必要です。
pipを利用してtabula-pyをインストールします。下記ではjpypeも一緒にインストールします。tabula-pyのみ指定してインストールした場合でも後ほどtabula.read_pdfを実行するとjpypeに関するエラーが表示されるのでjpypeを追加でインストールすることになります。
% pip install tabula-py[jpype]
pip listコマンドでインストールされたライブラリのバージョンを確認します。
% pip list
Package Version
--------------- ------------
distro 1.8.0
JPype1 1.4.1
numpy 1.26.2
packaging 23.2
pandas 2.1.4
pip 23.3.1
python-dateutil 2.8.2
pytz 2023.3.post1
setuptools 65.5.0
six 1.16.0
tabula-py 2.9.0
tzdata 2023.3
インストールしたtabulaを利用してPDFを読み込みます。
import tabula
df = tabula.read_pdf("sales.pdf", pages="all")
print(df)
実行するとJAVA_NOT_FOUND_ERRORのエラーとなりJavaが必要であることがわかります。
% python test.py
//略
raise JavaNotFoundError(JAVA_NOT_FOUND_ERROR)
tabula.errors.JavaNotFoundError: `java` command is not found from this Python process.Please ensure Java is installed and PATH is set for `java`
Javaのインストール
Javaのインストールを行うためにhttps://www.oracle.com/jp/java/technologies/downloads/を開きます。
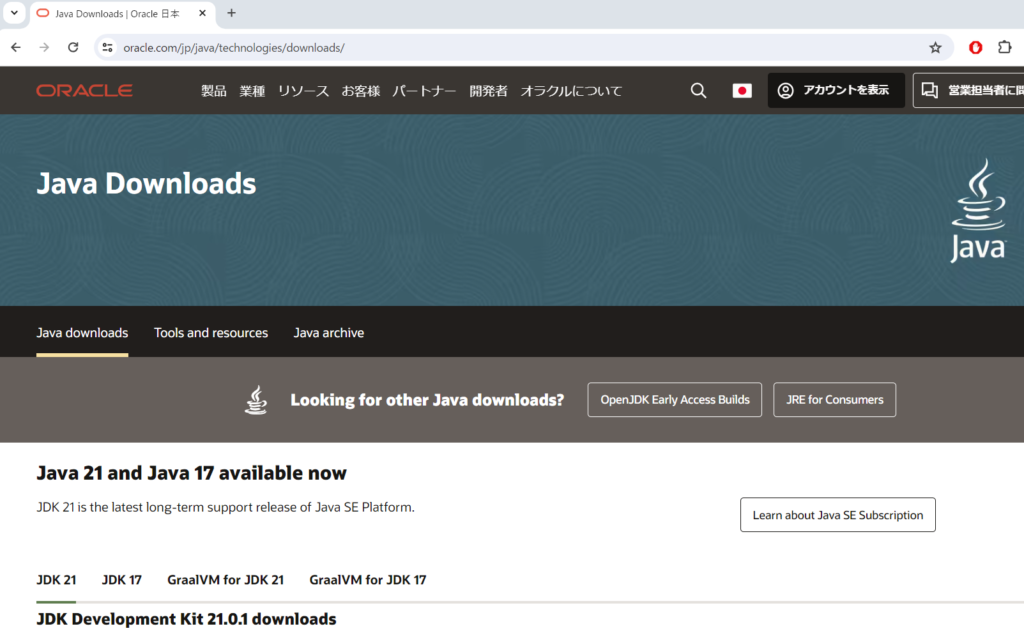
スクロールするとOS選択のタブが表示されます。本記事ではWindowsを利用しているのでx64 MSI Installのリンクをクリックします。
クリックするとダウンロードが開始されるのでインストールを行ってください。
インストールが完了してjava -versionを実行するとインストールしたJavaのバージョンを確認することができます。
% java -version
java version "21.0.1" 2023-10-17 LTS
Java(TM) SE Runtime Environment (build 21.0.1+12-LTS-29)
Java HotSpot(TM) 64-Bit Server VM (build 21.0.1+12-LTS-29, mixed mode, sharing)
JAVA_HOMEの設定
Javaのインストールが完了したので再度test.pyを実行すると環境変数のJAVA_HOMEの設定に関するエラーが発生します。
% python test.py
//
raise JVMNotFoundException("No JVM shared library file ({0}) "
jpype._jvmfinder.JVMNotFoundException: No JVM shared library file (jvm.dll) found. Try setting up the JAVA_HOME environment variable properly.
Windows画面の検索バーに環境変数を入力して検索を行いユーザの環境変数にJAVA_HOMEを追加してください。追加する値はJavaのバージョンによって異なります。
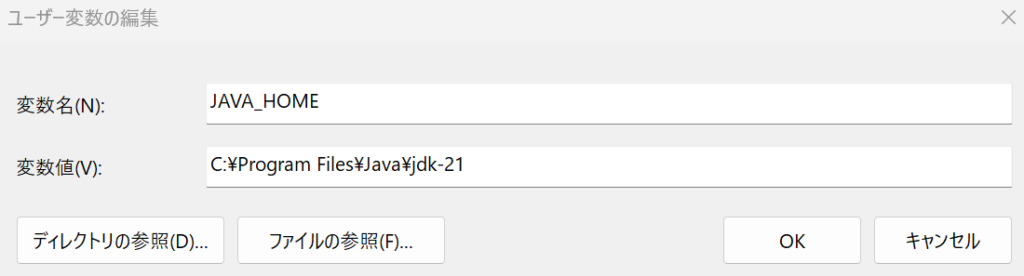
JAVA_HOMEを設定後に再度実行するとPDFのテーブルの内容を取得することができます。テーブル以外のテキストの文字列は無視されます。
% python test.py
12月 13, 2023 2:09:32 午後 org.apache.fontbox.ttf.CmapSubtable processSubtype14
警告: Format 14 cmap table is not supported and will be ignored
12月 13, 2023 2:09:32 午後 org.apache.fontbox.ttf.CmapSubtable processSubtype14
警告: Format 14 cmap table is not supported and will be ignored
[ Unnamed: 0 日付 販売数 備考
0 1 2023/9/1 100 NaN
1 2 2023/9/2 40 NaN
2 3 2023/9/3 32 NaN
3 4 2023/9/4 487 NaN
4 5 2023/9/5 2 NaN
5 6 2023/9/6 38 NaN]
EXCELファイルへの保存
tabula.read_pdfで戻される型を確認しておきます。
import tabula
df = tabula.read_pdf("sales.pdf", pages="all")
print(type(df))
実行するとlistであることがわかります。複数の表がある場合はリストとして保存されます。
<class 'list'>
listの0番目に保存されているのでdf[0]でテーブルをDataFrameとして取得することができます。
DataFrameなのでto_excelでEXCELファイルに保存することができます。index=Falseを設定することでindexをEXCELに保存しないようにすることができます。
import tabula
df = tabula.read_pdf("sales.pdf", pages="all")
df[0].to_excel("sales.xlsx",index=False)
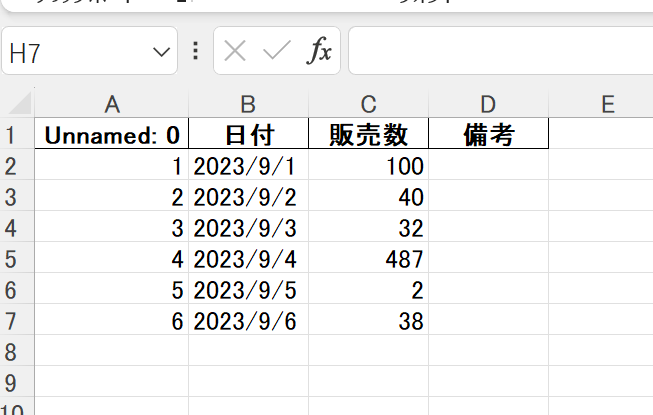
上記の例ではシンプルなデータでしたがヘッダーの文字に改行がある場合に綺麗に表が取得できない場合があります。特にセルを分ける線がある場合はオプションの”lattice=True”に設定することで綺麗に取得することができます。
import tabula
df = tabula.read_pdf("sales.pdf", lattice=True, pages="all")
df[0].to_excel("sales.xlsx",index=False)
tabulaを利用した場合はJavaのインストールなど他のライブラリに比べて利用するまでに手間がかかりますが利用すればPDFから簡単に表を取得してEXCELファイルに保存することができます。
pdfplumberを利用した場合
pdfplumberはtabulaのようにJavaを追加インストールする必要はなくPythonライブラリのインストールだけでPDFから表のデータを取得することができます。
PDFから表のデータを取り出してEXCELファイルに保存するために以下のパッケージのインストールを行います。
% pip install pdfplumber pandas openpyxl
コードは下記のようになります。
import pdfplumber
import pandas as pd
with pdfplumber.open("sales.pdf") as pdf:
all_tables = []
for i, page in enumerate(pdf.pages):
tables = page.extract_tables()
for table in tables:
df = pd.DataFrame(table)
all_tables.append(df)
with pd.ExcelWriter("sales.xlsx", engine="openpyxl") as writer:
for i, table_df in enumerate(all_tables):
table_df.to_excel(writer, sheet_name=f"Table_{i+1}", index=False)
実行するとsales.xlsxファイルにPDFから抽出した表データが保存されます。
このようにpdfplumberはPythonライブラリのみでPDFファイルから表形式のデータのみを抽出することができます。
camelotを利用した場合
camelotを利用してPDFから表形式のデータを利用できる形で抽出するためにはGhostScriptのインストールが必要となります。GhostScriptのインストールなしでも動作しますがその場合は表形式としてではなくpypdfのようにテキストデータとしてのみ抽出されました。表形式として抽出するためにはGhostScriptのインストールが必要となります。
PDFから表のデータを取り出してEXCELファイルに保存するために以下のパッケージのインストールを行います。
% pip install camelot pandas openpyxl
コードは下記のようになります。
import camelot
import pandas as pd
tables = camelot.read_pdf("sales.pdf", pages="all")
all_tables = []
for i, table in enumerate(tables):
all_tables.append(table.df)
with pd.ExcelWriter("sales.xlsx", engine="openpyxl") as writer:
for i, table_df in enumerate(all_tables):
table_df.to_excel(writer, sheet_name=f"Table_{i + 1}", index=False)
テーブルの罫線がしっかりあるにも関わらず列の区切りがうまくいかない場合にはオプションのsplit_text=Trueに設定するとうまく動作しました。
tables = camelot.read_pdf("sales.pdf", pages="all", flavor="lattice", split_text=True)
このようにPythonではPDFから表形式データを抽出するためのライブラリが複数あります。今回利用したデータがシンプルだったのでpypdfを除きどのライブラリでも問題なく抽出することができました。しかし、表の構造が複雑になるとうまく動作しないライブラリもあるかもしれません。その際はここで紹介した別のライブラリを利用して動作確認を行ってみてください。最初に試すのはPythonだけで動作するpdfplumberだと思いますのでぜひPDFから表を抽出したい場合には参考にしてください。