5分で理解するOllama!ローカル環境で動くAIを手軽に構築

AIの勉強を始めたばかりで、Ollamaという名前を初めて聞いたんだけど、「Ollamaは一体どんなツールなの?どうやって使うんだろう?」そんな疑問をお持ちではありませんか?この記事では、Ollamaを初めて使う方でも分かりやすいようにOllamaのインストール方法、モデルのダウンロード方法、そしてOllamaを使ったチャットの利用方法について詳しく説明します。Ollamaの設定は、コマンドライン操作とPython(or Docker)が出てくるため、初心者の方には少し難しく感じる部分があるかもしれませんがこの記事を読み終える頃にはOllamaの基本的な使い方が理解できるでしょう。OllamaはmacOS、Linux、Windowsに対応していますが、今回はmacOSを例に説明していきます。
また、ChatGPTのようにブラウザ上で手軽にチャットを楽しみたい方のために、Ollamaと連携できる”Open WebUI”というツールについてもご紹介します。 これを使えば、より直感的にOllamaを活用することができます。
目次
Ollamaとは
ChatGPTのようなAIを、自分のPCで動かしてみたいと思ったことはありませんか?そんなときに役立つのがOllamaです。
Ollamaは自分のPC上でAIを動かすためのプラットフォームです。これを使うとPC上でAIとチャットすることが可能になります。ただし、Ollama単体ではAIを動かすことはできません。OllamaはAIを動かす土台のようなもので、実際に動かすためには、大規模言語モデル(LLM)が必要です。
Ollamaは複数種類のAIモデルをサポートしているため、用途や目的に応じて好きなモデルを選んで動かすことができます。OllamaとAIモデルの関係が分かりにくい場合は、スマートフォン(Ollama)とアプリ(AIモデル)の関係をイメージすると理解しやすいでしょう。。

Ollamaのメリット
- Ollamaは無料です
- Ollama, モデルのダウンロードが完了したらインターネットがない環境でも利用できます
- 手元のローカルのPCでAIを動かすことができるとAIを動かすために入力した情報が外部に漏れることはありません。
Ollamaのデメリット
- モデルによっては一般的なPCでは動作しなかったり遅くなったりすることがあります。
- モデルによっては非常に大きなファイルサイズになることがあり、ダウンロード時間やストレージを大きく消費します。
- Ollamaはプラットフォームですがすべてのモデルを利用することができないため利用できるモデルに制限があります。
Ollamaのダウンロード
OllamaをmacOSにインストールする方法にはHomebrewを利用して(brew install ollama)でも行うことができますが本文書ではollama.comからダウンロードを行ってインストールを行います。
画面中央になるDownloadボタンをクリックします。
Download for macOSボタンをクリックしてダウンロードが完了すると”Ollama-darwin.zip”ファイルがダウンロードされます。zipファイルなので展開するとOllamaファイルが展開されるので”Shift+Cmd+A”ボタンでアプリケーションフォルダを開いて移動させます。
Ollamaのインストール
アプケーションフォルダに移動した後にOllamaを実行します。実行するとインストール画面が表示されます。”Welcome to Ollama”画面が表示されるので”Next”ボタンをクリックします。
コマンドラインのインストール画面が表示されます。Ollamaではコマンドラインを利用してモデルのダウンロードやモデルの削除を行うことができます。”install”ボタンをクリックしてください。

インストールが完了すると以下の画面が表示されます。表示されているコマンド(ollama run llama3.2)を実行するとllama3.2モデルがローカルに存在しない場合、自動的にダウンロードが開始されます。ダウンロードが完了するとチャットが開始され、AIとの対話が可能になります。2回目以降の実行時には、既にモデルがローカルに保存されているためダウンロードを行わずすぐにチャットを開始することができます。

Ollamaの動作確認
インストールしたollamaのバージョン(0.4.2)とコマンドのパスを確認して、ollama run llama3.2を実行してllama3.2モデルのダウンロードを行います。ダウンロードが完了するとチャットが可能となります。
% ollama -v
ollama version is 0.4.2
% which ollama
/usr/local/bin/ollama
% ollama run llama3.2
pulling manifest
pulling dde5aa3fc5ff... 100% ▕████████████████▏ 2.0 GB
pulling 966de95ca8a6... 100% ▕████████████████▏ 1.4 KB
pulling fcc5a6bec9da... 100% ▕████████████████▏ 7.7 KB
pulling a70ff7e570d9... 100% ▕████████████████▏ 6.0 KB
pulling 56bb8bd477a5... 100% ▕████████████████▏ 96 B
pulling 34bb5ab01051... 100% ▕████████████████▏ 561 B
verifying sha256 digest
writing manifest
success
>>> Send a message (/? for help)
日本語も利用できるか確認するために”ollamaについて”と質問してみました。南米の伝統的な土器について返答がありました。英語で”tell me about ollama”と質問しても同様の回答でした。
>>> ollamaについて教えて
オラマ(Olla)とは、南米の伝統的な土器です。主にコロンビアやエクアドルで使用
されています。
オラマの特徴:
//略
チャットを終了したい場合は”Use Ctrl + d or /bye to exit.”で終わらせることができます。
ダウンロードしたモデルollama listコマンドで確認することができます。モデルのサイズが2.0GBであることがわかります。
% ollama list
NAME ID SIZE MODIFIED
llama3.2:latest a80c4f17acd5 2.0 GB 10 minutes ago
そのほかのコマンドについては-hオプションをつけることで確認できます。
% ollama -h
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
このようにollamaを利用することで手元のPCでも簡単にAIを利用できるようになりました。
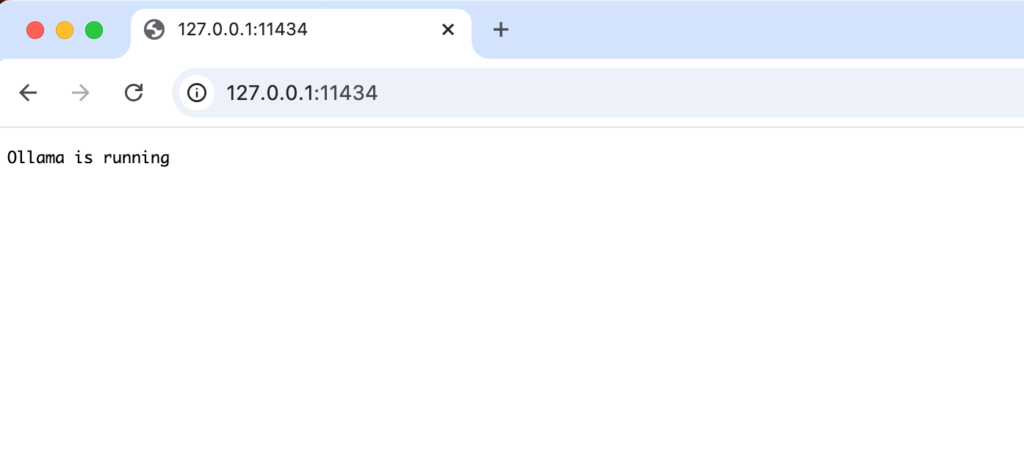
サーバとしても起動しているのブラウザからhttp://127.0.0.1:11434にアクセスすると”Ollama is running”のメッセージが表示されます。起動していない場合は”ollama serve”コマンドで起動させることができます。
APIでの動作確認
チャットではなくアプリケーションからAIにリクエストを送信することができます。そのためにはOllamaがサーバとして起動している必要があります。サーバと起動してしていない場合は”ollama serve”コマンドを実行することで開始することができます。
% ollama serve
2024/11/19 16:13:34 routes.go:1189: INFO server config env="map[HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_KEEP_ALIVE:5m0s OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/Users/mac/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: http_proxy: https_proxy: no_proxy:]"
//略
サーバにリクエストを送信する場合のエンドポイントのURLは/api/generateです。APIについての情報はOllamaのGithubのページから確認することができます。
この/api/generateに対してcurlコマンドでPOSTリクエストを送信することで動作確認を行います。modelには”llama3.2″を利用してプロンプトには”Hello”を設定しています。modelプロパティは必須なのでダウンロードして利用できるモデル名を指定する必要があります。
% curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "Hello"
}'
{"model":"llama3.2","created_at":"2024-11-19T07:17:15.597119Z","response":"How","done":false}
{"model":"llama3.2","created_at":"2024-11-19T07:17:15.690893Z","response":" can","done":false}
{"model":"llama3.2","created_at":"2024-11-19T07:17:15.788948Z","response":" I","done":false}
{"model":"llama3.2","created_at":"2024-11-19T07:17:15.886181Z","response":" assist","done":false}
{"model":"llama3.2","created_at":"2024-11-19T07:17:15.983084Z","response":" you","done":false}
{"model":"llama3.2","created_at":"2024-11-19T07:17:16.079704Z","response":" today","done":false}
{"model":"llama3.2","created_at":"2024-11-19T07:17:16.176173Z","response":"?","done":false}
//略
Ollamaサーバから戻されるJSONデータのresponseプロパティをつなげていくと”How can I assist you today?”の文字を確認することができます。再度同じ”Hello”としても異なる回答が戻ってくることも確認できます。(Hello! It’s nice to meet you. Is there something I can help you with, or would you like to chat?)
このようにAPIサーバとして利用できるのでReactやVue.jsなどのJavaScriptフレームワークまたDifyなどのツールからもアクセスすることができます。
Error: listen tcp 127.0.0.1:11434: bind: address already in use
ollama serveコマンドを実行するとサーバがすでに起動しているので”
Error: listen tcp 127.0.0.1:11434: bind: address already in use”が表示される場合があります。lsof -i :11434でプロセスを確認してkillしたり、ps aux | grep ollamaでプロセスを確認してkillしても停止しません。その場合は移動→アプリケーションフォルダに移動してOllamaアプリケーションを起動してツールバーに表示されるOllamaのメニューから”Quit Ollama”を実行してください。
ChatGPTのようにブラウザ上からチャットをしたい
Ollamaとモデルを利用してコマンドラインでチャットを行うことができましたがChatGPTのようにブラウザ上でチャットを行うことができないのかと疑問に思った人も多いかと思います。別にインストールが必要になるツールですがOpen WebUIを利用することでOllamaと連携してChatGPTのようにブラウザ上でチャットを行うことができます。
Open WebUIとは
Open WebUIは、ブラウザの画面を通してローカル環境で大規模言語モデル(LLM)を簡単に実行・操作するためのツールです。Open WebUIを利用することでChatGPのようにインタラクティブにAIモデルとやりとりすることができます。
Open WebUIをローカルPCで利用する方法にはPythonのpipコマンドを利用して手動でインストールする方法とDocker(マニュアルではこちらを推奨)を利用してインストールする必要があります。pipコマンドを利用してインストールする場合には依存関係の問題をさけるためPythonのバージョン3.11を利用を推奨しています。今回利用するPCにPythonのバージョン3.11がインストールされていたのでpipコマンドでインストールを行い利用方法を説明していきます。
インストール方法についてはOpen WebUIのGithubのページから確認することができます。ページにはPython pipとDockerでの方法が記載されています。
Pythonを利用したインストール
インストールする前にpythonのバージョンを確認しておきます。-Vオプションをつけて実行することでバージョンを確認することができます。3.11であることを確認してください。
% python3 -V
Python 3.11.7
PCのグローバルの環境に影響を与えないためPythonの仮想環境をvenvを利用してインストールを行います。実行するとmyenvという名前のフォルダが作成されます。source myenv/bin/activate は、Pythonで仮想環境を有効化するためのコマンドです。実行することで環境変数や設定が現在利用しているシェルに反映されます。sourceコマンドは必ず実行してください。
% python3 -m venv myenv
% source myenv/bin/activate
pipコマンドで利用してopen-webuiのインストールを行います。インストールに少し時間がかかります。
(myenv) % pip install open-webui
インストールが完了するとopen-webuiコマンドが利用できるようになるのでopen-webui serveコマンドで起動します。最初の起動には時間がかかります。
% open-webui serve
//略
___ __ __ _ _ _ ___
/ _ \ _ __ ___ _ __ \ \ / /__| |__ | | | |_ _|
| | | | '_ \ / _ \ '_ \ \ \ /\ / / _ \ '_ \| | | || |
| |_| | |_) | __/ | | | \ V V / __/ |_) | |_| || |
\___/| .__/ \___|_| |_| \_/\_/ \___|_.__/ \___/|___|
|_|
v0.3.35 - building the best open-source AI user interface.
https://github.com/open-webui/open-webui
INFO: Started server process [14365]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
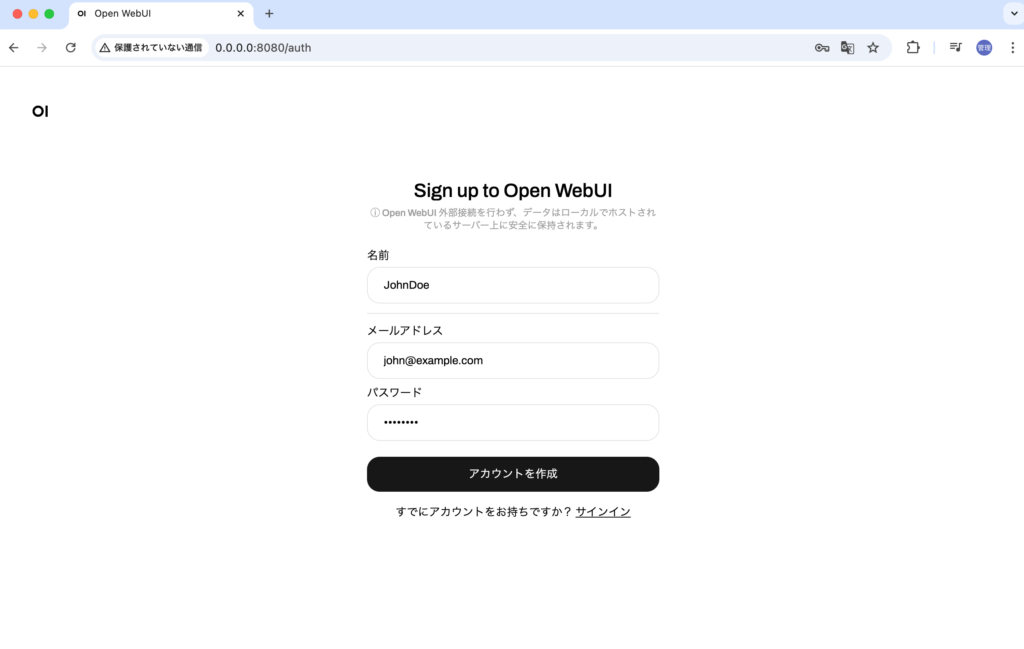
Open WebUIはポート8080で起動するのでhttp://0.0.0.0:8080でアクセスすることができます。 ブラウザ上にはOIという文字列が表示されますがしばらくするとサインインページが表示されます。初めてアクセスした場合はアカウントがないのでサインアップする必要があります。任意の名前、メールアドレスとパスワードを入力してアカウントを作成してください。
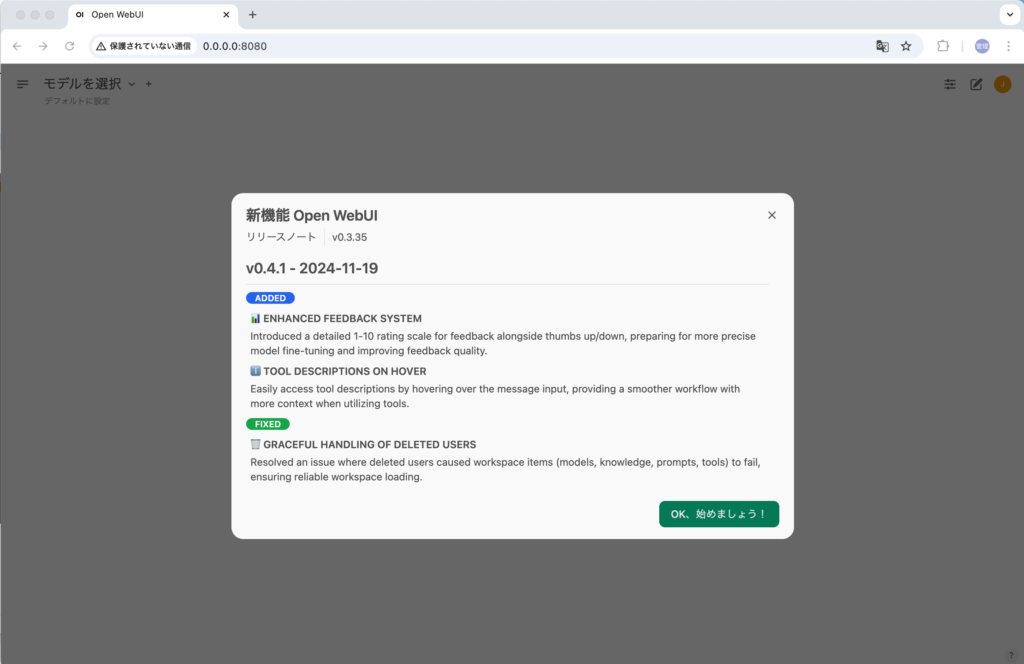
サインアップするとOpen WebUIのバージョン情報が表示されます。”OK. 始めましょう!”をクリックしてください。
サインアップを行うとブラウザ上からチャットを開始することができます。試しに”Hello”と入力します。モデルが選択されていませんと表示された場合は左上からモデルを選択する必要がありますがOllamaのサーバが起動していない場合にはモデルの選択もできません。エラーが出た場合は”ollama serve”コマンドでサーバを起動してください。
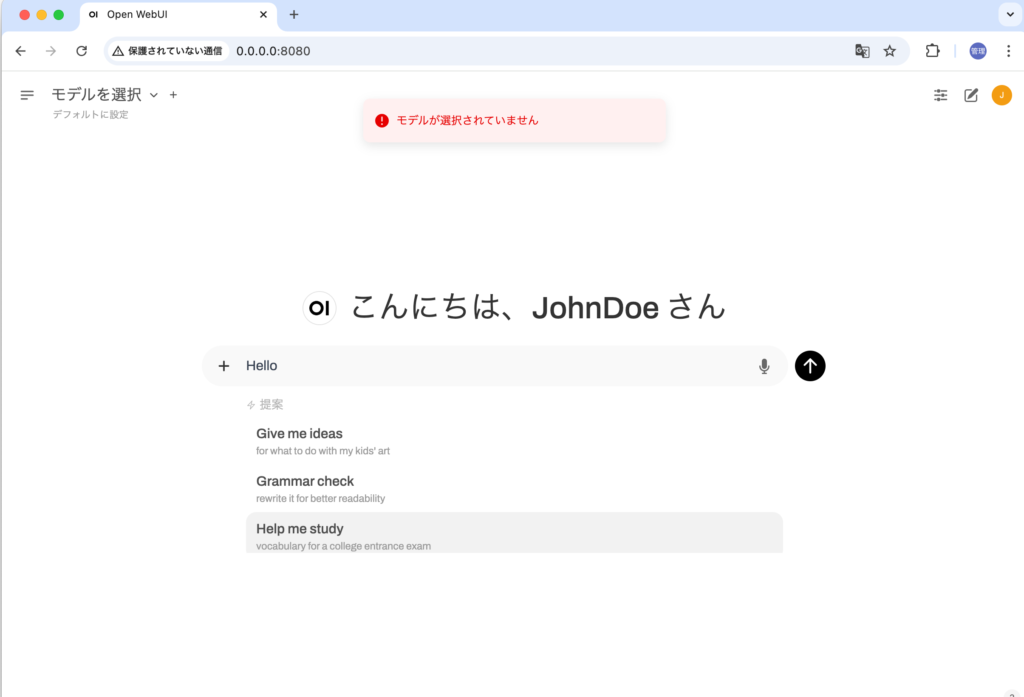
“ollama serve”コマンドを実行してサーバを起動してもモデルが選択できない場合はブラウザをリロードしてください。
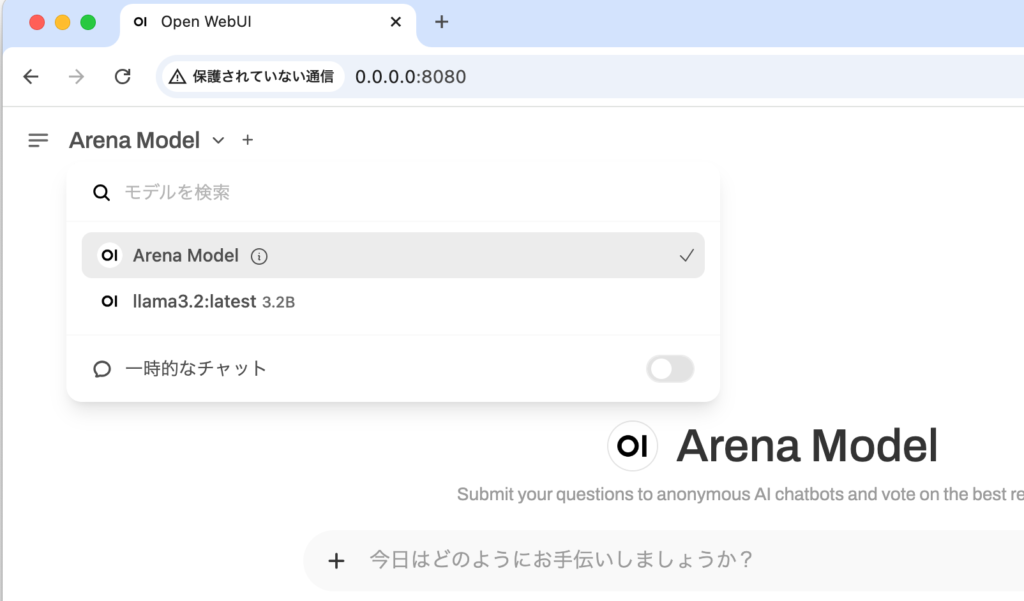
モデルをllama3.2:latest 3.2Bに選択後、”Hello”のメッセージを入れて実行すると回答が表示されます。
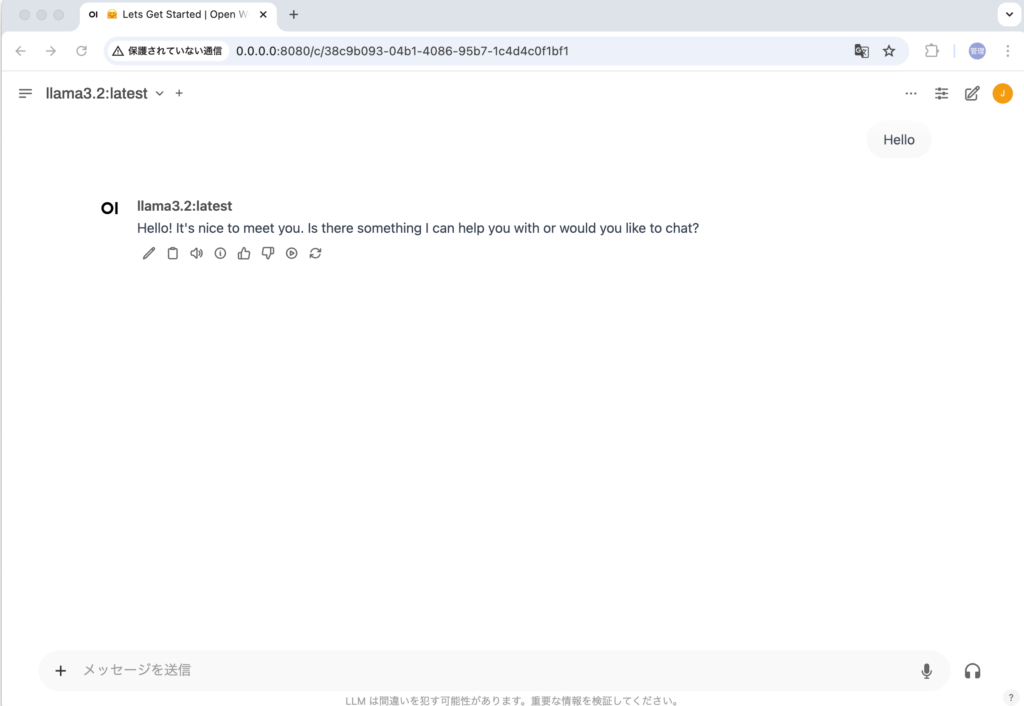
このようにOllamaとOpen WebUIを組み合わせることでChatGPTのようなブラウザ上でのチャットを行うことができるようになりました。