初心者必見!DifyナレッジAPIの導入方法と効率的な活用術

Difyを活用してRAG(Retrieval-Augmented Generation)を行う際、多くの人がDifyの画面を通じてナレッジにファイルをアップロードしているのではないでしょうか。しかし、Difyの画面を使わずにAPIを経由してナレッジにアクセスできればさらなる業務効率化が可能になると考えたことはありませんか?
実は、Difyには「ナレッジAPI」という機能が備わっておりこのAPIを利用することでプログラム経由でナレッジの情報に直接アクセスすることが可能です。
DifyはGUIを活用してノーコードでアプリを作成できる点が最大のメリットですが、APIを利用することでそのメリットをさらに拡張することができます。具体的には、自動化や外部システムとの連携が可能になり業務フローを一層効率化できます。
Difyをすでに使いこなしている方やさらなる効率化に興味のある方は、ぜひ本記事で「ナレッジAPI」で何ができるのかを確認してみてください。新たな活用方法が見つかるかもしれません。
目次
Difyのナレッジとは何ですか?
簡単に言うとDifyにおけるナレッジは大規模言語モデル(LLM:ChatGPTなど)が持っていない情報を保存するための場所です。Difyで作成されるアプリケーション(チャットボットなど)には必ずLLMが組み込まれていますがすべての情報を保持しているわけではありません。ユーザーからの問い合わせに正確に答えさせるためには事前に回答に必要な情報や知識を与えておく必要があります。その情報を保存する場所が「ナレッジ」です。
例えば、ECサイトのチャットボットを作成する場合を考えてみましょう。ECサイトごとに送料やキャンセルの条件が異なります。LLMは一般的な知識に基づいて回答を生成できますが、特定のECサイトに関する詳細な情報は持っていません。そのため、ナレッジを活用してこれらの情報を事前に与える必要があります。
このように、チャットボットが必要とする特定の情報を事前にナレッジに登録しておくことで、ユーザーからの質問に迅速かつ正確に回答できるようになります。ナレッジを適切に活用することで、より高度なカスタマイズや業務効率化が実現します。
ナレッジAPIのシークレットキーの取得
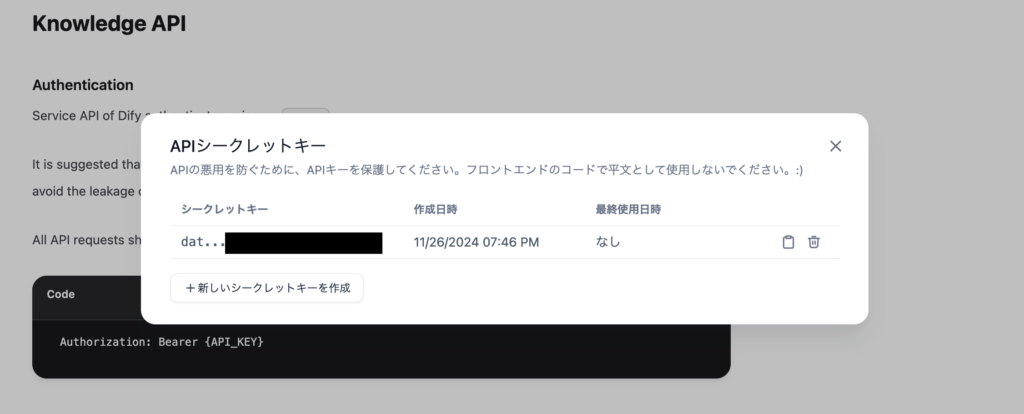
Difyのナレッジ画面に移動します。ナレッジ画面の左上部には”ナレッジ”と”API”のリンクを確認することができます。APIを利用する場合、APIシークレットキーの取得が必要となるため、”API”のリンクをクリックします。
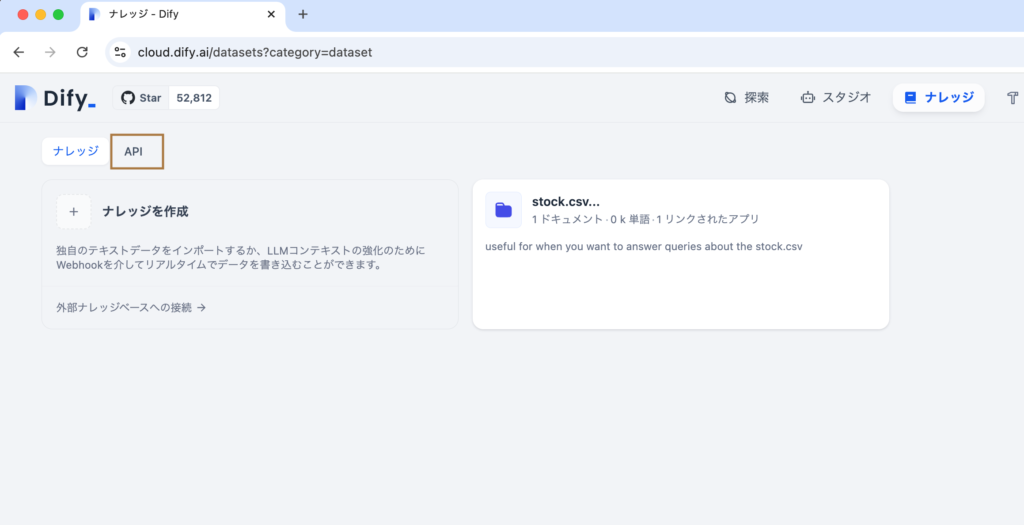
APIのリンクをクリックするとナレッジAPIの利用方法の説明ページが表示されます。APIのキーを取得するために右上にある”APIキー”のボタンをクリックします。
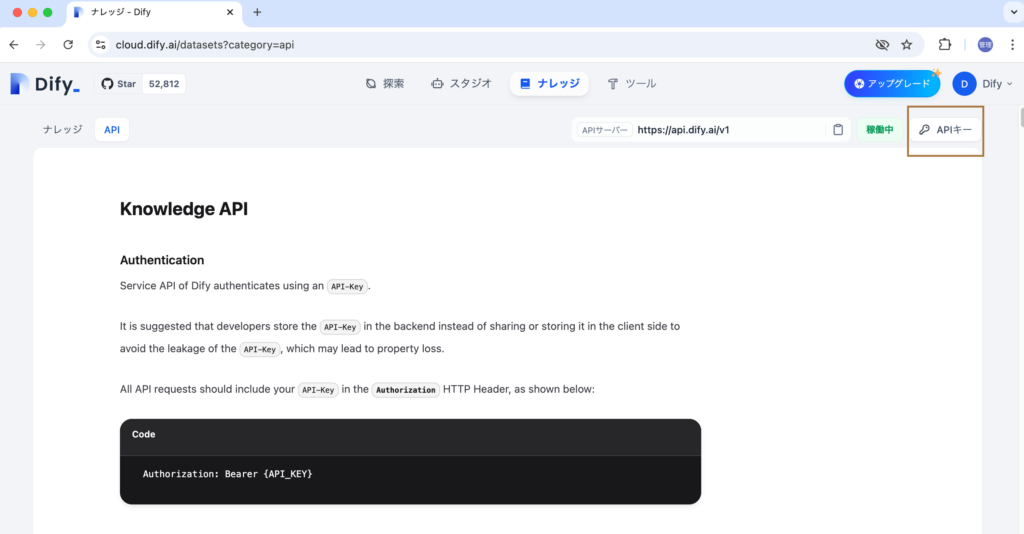
APIシークレットキーの一覧表示画面が表示されますが、キーが未作成なので作成済みのキーの情報は表示されません。新しいシークレットキーを作成するので”新しいシークレットキーを作成”ボタンをクリックしてください。
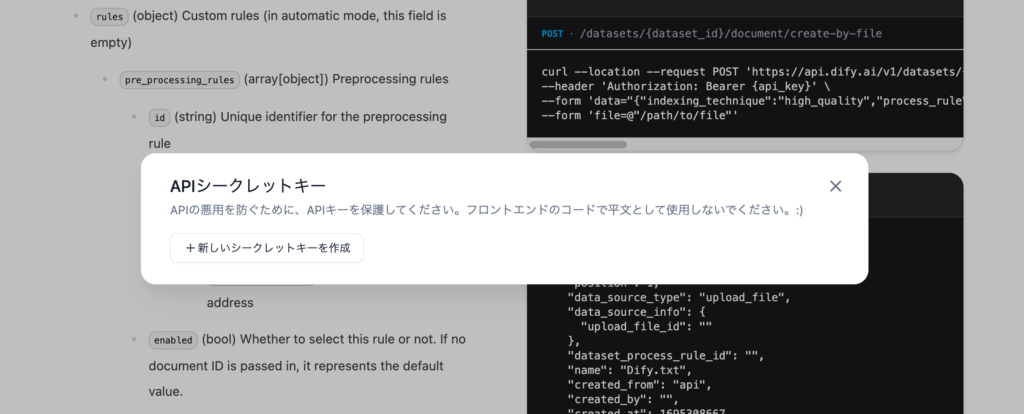

シークレットキーが表示されているのでコピーして保存してください。
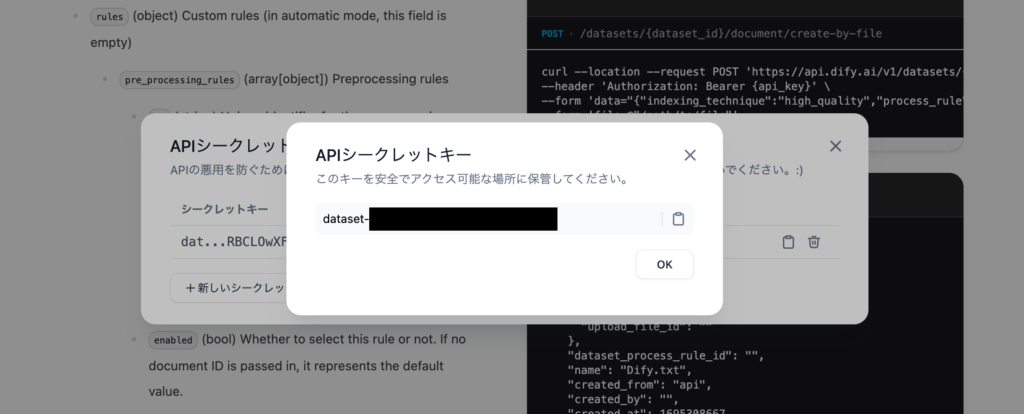
DifyのナレッジAPIのシークレットキーは一度表示されたら再度確認できないものではなくAPIシークレットキーの一覧画面でキーのコピーを行うことができます。不必要になった場合はゴミ箱アイコンをクリックしてシークレットキーの削除を忘れないで行ってください。
ナレッジの理解
ナレッジAPIを使いこなすためにはナレッジの理解が必要となります。
ナレッジはデータセット、ドキュメント、セグメントの3階層で構成されています。ナレッジを作成してファイルをアップロードした場合はデータセットとドキュメントが一度に作成されます。ドキュメントがファイルに対応して、その上の階層がデータセットになります。データセットの中には複数のファイルを登録することができます。
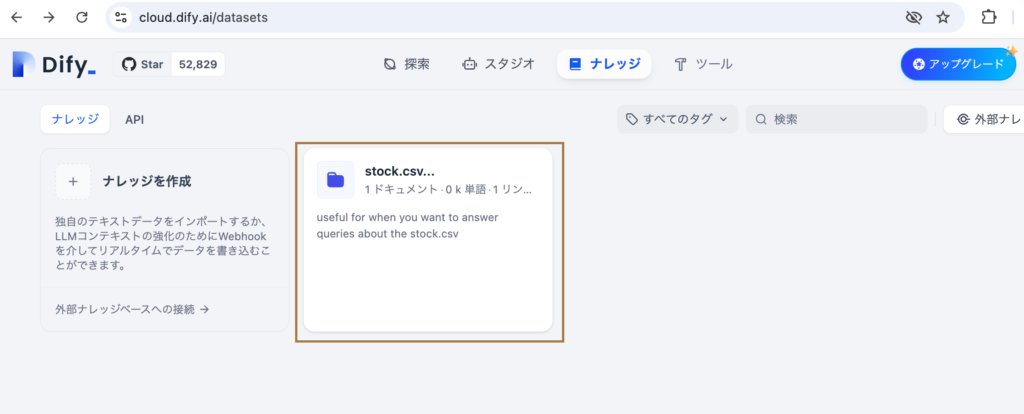
これらの階層を画面を使って説明していきます。ナレッジの画面にアクセスすると表示されるのがデータセットです。四角で囲まれた枠がデータセットに対応します。複数のファイルが保存できるのでフォルダのアイコンが表示されています。
データセットをクリックするとその下の階層にあたるドキュメントの一覧画面が表示されます。
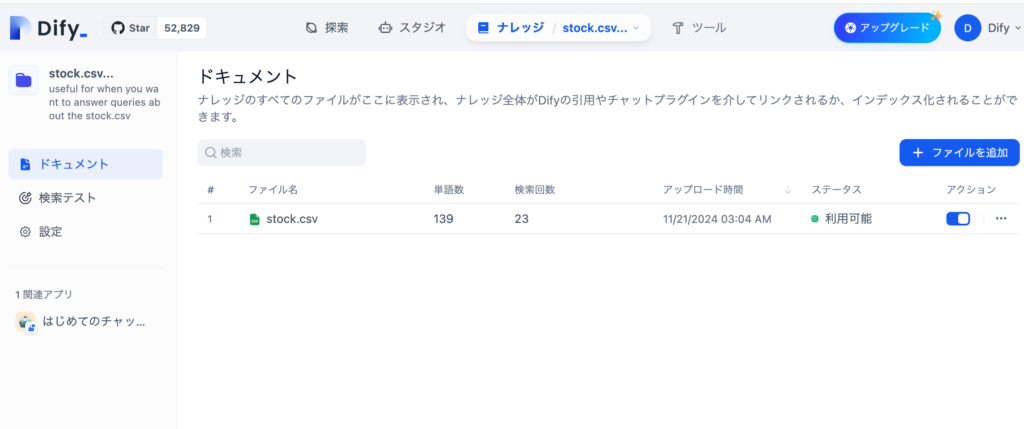
画面に”ファイル追加”ボタンが表示されているようにデータセットにドキュメントを追加することができます。
さらにドキュメントをクリックするとセグメントを確認することができます。一つ一つの塊がセグメントです。
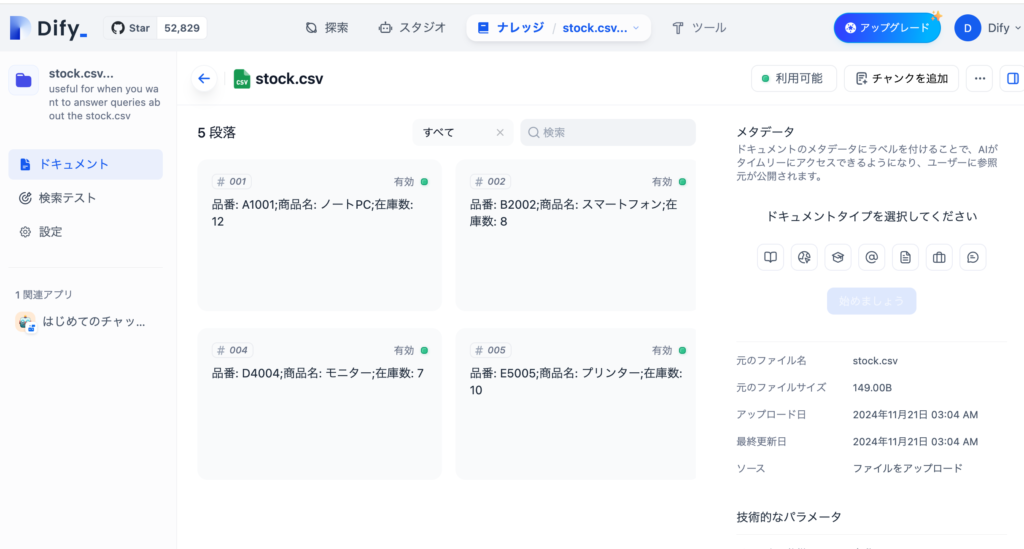
アップロードしたファイルstock.csvの1行がセグメントに対応します。
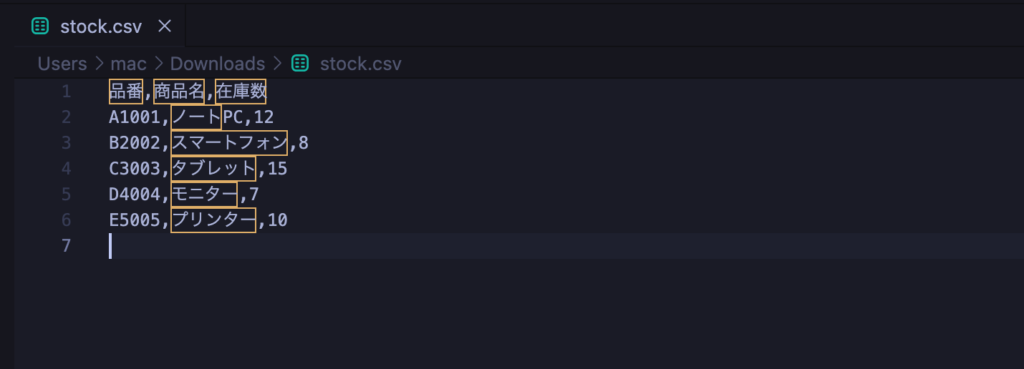
このようにナレッジはデータセット、ドキュメント、セグメントの3つの階層で構成されています。
APIを利用してナレッジを操作するためにはデータセット、ドキュメント、セグメントをそれぞれ識別するためのIDが必要となります。
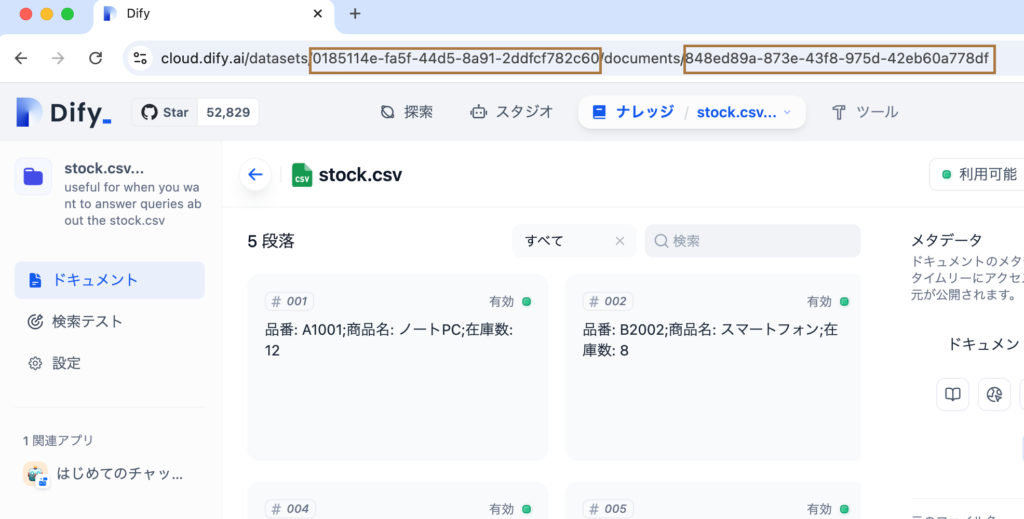
データセットID(dataset_id)やドキュメントID(documennt_id)はAPIを利用して取得したデータから確認することができますがURLで確認することもできます。四角で囲んだ文字列がIDでです。
ナレッジAPIの動作確認
ナレッジAPIの取得とナレッジの構造が理解できたので実際にナレッジAPIの動作確認を行っていきます。
保存されているナレッジの取得
Difyに登録されているナレッジの一覧は下記のcurlコマンドを利用して取得することができます。{api_key}の部分には取得したシークレットキーを設定してください。api_keyを設定する場合は{}(カッコ)は必要ありません。そのままシークレットキーの文字列を設定してください。
% curl --location --request GET 'https://api.dify.ai/v1/datasets?page=1&limit=20' \
--header 'Authorization: Bearer {api_key}'
実行するとJSONデータとしてレスポンスが戻されます。ナレッジにstock.csvファイルのみ登録されているため戻されるdataの配列には1つしか情報が入っていませんが、複数登録されている場合は複数のナレッジ登録情報が表示されます。表示されているidはstock.csvが含まれているデータセットのidです。
{
"data": [
{
"id": "0185114e-fa5f-44d5-8a91-2ddfcf782c60",
"name": "stock.csv...",
"description": "useful for when you want to answer queries about the stock.csv",
"provider": "vendor",
"permission": "only_me",
"data_source_type": "upload_file",
"indexing_technique": "high_quality",
"app_count": 1,
"document_count": 1,
"word_count": 139,
"created_by": "72305bd8-fd42-444a-9585-3255c2d3f58b",
"created_at": 1732176245,
"updated_by": "72305bd8-fd42-444a-9585-3255c2d3f58b",
"updated_at": 1732177554,
"embedding_model": "text-embedding-3-large",
"embedding_model_provider": "openai",
"embedding_available": true,
"retrieval_model_dict": {
"search_method": "semantic_search",
"reranking_enable": false,
"reranking_mode": null,
"reranking_model": {
"reranking_provider_name": null,
"reranking_model_name": null
},
"weights": null,
"top_k": 3,
"score_threshold_enabled": false,
"score_threshold": 0.0
},
"tags": [],
"external_knowledge_info": {
"external_knowledge_id": null,
"external_knowledge_api_id": null,
"external_knowledge_api_name": null,
"external_knowledge_api_endpoint": null
},
"external_retrieval_model": {
"top_k": 3,
"score_threshold": 0.0,
"score_threshold_enabled": false
}
}
],
"has_more": false,
"limit": 20,
"total": 1,
"page": 1
}

ワークフローのHTTPリクエストブロック
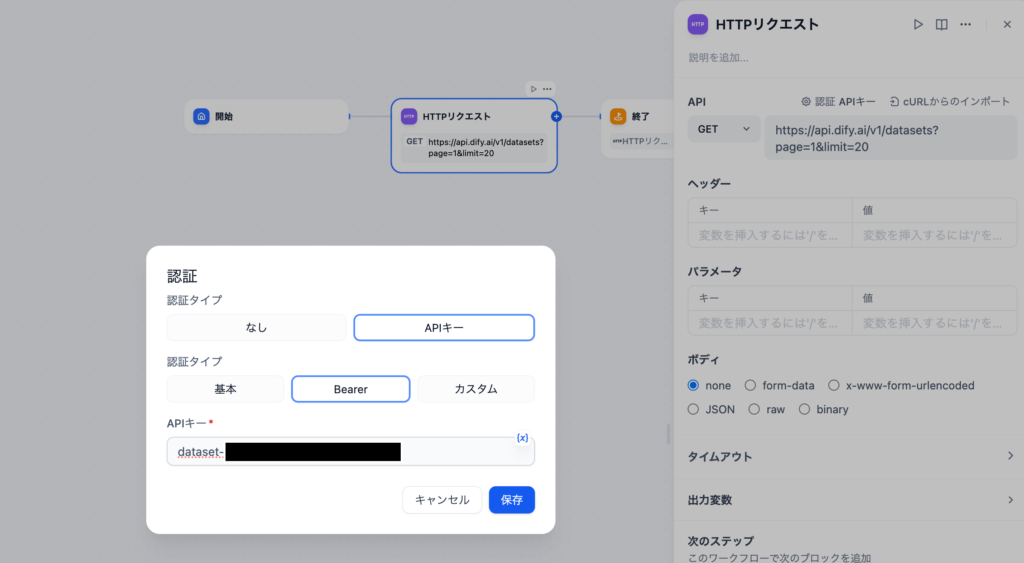
curlコマンドではなくDifyのワークフローのHTTPリクエストブロックを利用してもナレッジAPIにアクセスすることはできます。認証のAPIキーを設定する場合は認証タイプにBearerを設定してナレッジAPIのシークレットキーを設定してください。
JavaScriptのfetch関数
JavaScriptの場合はfetch関数を利用して下記のコードで取得することができます。
const response = await fetch(
'https://api.dify.ai/v1/datasets?page=1&limit=20',
{
method: 'GET',
headers: {
Authorization: `Bearer {api_key}`,
},
}
);
const data = await response.json();
console.log(data);
ドキュメント一覧の取得
データセットIDが分かれば、そのデータセットに含まれているドキュメントの一覧を取得することができます。データセットIDはナレッジリストで取得したものを利用します。各自が取得したdataset_idとapi_keyを設定して実行してください。
% curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents' \
--header 'Authorization: Bearer {api_key}'
実行するとドキュメントの一覧が取得できます。ここで表示されているidがstock.csvのドキュメントのidです。
{
"data": [
{
"id": "848ed89a-873e-43f8-975d-42eb60a778df",
"position": 1,
"data_source_type": "upload_file",
"data_source_info": {
"upload_file_id": "f96be856-c375-46f6-9e02-e739446c3653"
},
"data_source_detail_dict": {
"upload_file": {
"id": "f96be856-c375-46f6-9e02-e739446c3653",
"name": "stock.csv",
"size": 149,
"extension": "csv",
"mime_type": "text/csv",
"created_by": "72305bd8-fd42-444a-9585-3255c2d3f58b",
"created_at": 1732176226.962292
}
},
"dataset_process_rule_id": "614f216d-5862-4de8-841c-8707bf1a88c6",
"name": "stock.csv",
"created_from": "web",
"created_by": "72305bd8-fd42-444a-9585-3255c2d3f58b",
"created_at": 1732176245,
"tokens": 116,
"indexing_status": "completed",
"error": null,
"enabled": true,
"disabled_at": null,
"disabled_by": null,
"archived": false,
"display_status": "available",
"word_count": 139,
"hit_count": 23,
"doc_form": "text_model"
}
],
"has_more": false,
"limit": 20,
"total": 1,
"page": 1
}
JavaScriptの場合は以下のコードでドキュメント一覧を取得することができます。
const response = await fetch(
'https://api.dify.ai/v1/datasets/{dataset_id}/documents',
{
method: 'GET',
headers: {
Authorization: `Bearer {api_key}`,
},
}
);
const data = await response.json();
console.log(data);
セグメント一覧の取得
データセットのidとドキュメントのidを利用してドキュメントに含まれるセグメントの一覧を取得することができます。各自が取得したdataset_id, document_idとapi_keyを設定して実行してください。
% curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments' \
--header 'Authorization: Bearer {api_key}' \
--header 'Content-Type: application/json'
日本語はUnicodeエスケープ形式でエンコードされた文字列として戻されますが変換を行うと以下のようにセグメント情報が戻されます。セグメントには在庫情報が保存されています。
{
"data": [
{
"id": "3fd6d829-2374-4113-ae1a-7d9a2171b60b",
"position": 1,
"document_id": "848ed89a-873e-43f8-975d-42eb60a778df",
"content": "品番: A1001;商品名: ノートPC;在庫数: 12",
"answer": null,
"word_count": 28,
"tokens": 22,
"keywords": [
"12",
"品番",
"PC",
"商品",
"A1001",
"在庫数"
],
//略
JavaScriptを利用した場合には以下のように記述することができます。
const response = await fetch(
'https://api.dify.ai/v1/datasets/{datasets_id}/documents/{document_id}/segments',
{
method: 'GET',
headers: {
Authorization: `Bearer {api_key}`,
},
}
);
const data = await response.json();
console.log(data);
コンソールには以下のように表示されます。

ドキュメントの更新
例えば在庫数の問い合わせが行えるチャットボットを作成した時、在庫数は刻々と変換するのでAPIを利用して更新を行うことができれば正しい在庫数を回答することができます。ここでは動作確認がわかりやすいので在庫を利用しますがQ&Aなどのチャットボットでも実行する手順は同じです。

ここではstock.csvのドキュメントのセグメントの品番A1001の在庫数を12から0に更新します。ドキュメントの更新前の値は12であることが下記の画像からわかります。
APIを利用してドキュメントの更新を行います。stock.csvファイルを更新に利用しますがアップロード前に品番:A1001の在庫数の値を0に更新しています。ファイルはcurlコマンドを実行するフォルダの中にstock.csvという名前で保存しています。dataset_id, document_id, api_keyは各自の環境に合わせて設定を行ってください。
% curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/update_by_file' \
--header 'Authorization: Bearer {api_key}' \
--form 'file=@stock.csv'
実行すると下記のJSONデータが戻されます。
{
"document": {
"id": "848ed89a-873e-43f8-975d-42eb60a778df",
"position": 1,
"data_source_type": "upload_file",
"data_source_info": {
"upload_file_id": "0e37e035-120a-4a73-b762-8372cc09c9a1"
},
"data_source_detail_dict": {
"upload_file": {
"id": "0e37e035-120a-4a73-b762-8372cc09c9a1",
"name": "stock.csv",
"size": 148,
"extension": "csv",
"mime_type": "application/octet-stream",
"created_by": "72305bd8-fd42-444a-9585-3255c2d3f58b",
"created_at": 1732674176.68546
}
},
"dataset_process_rule_id": "614f216d-5862-4de8-841c-8707bf1a88c6",
"name": "stock.csv",
"created_from": "web",
"created_by": "72305bd8-fd42-444a-9585-3255c2d3f58b",
"created_at": 1732176245,
"tokens": 116,
"indexing_status": "waiting",
"error": null,
"enabled": true,
"disabled_at": null,
"disabled_by": null,
"archived": false,
"display_status": "queuing",
"word_count": 139,
"hit_count": 23,
"doc_form": "text_model"
},
"batch": "20241121080405805660"
}
品番A1001の在庫数はファイルのアップロード前は12でしたがstock.csvファイルで在庫数を0にしたのでファイルの更新が正常に行われていることが確認できました。
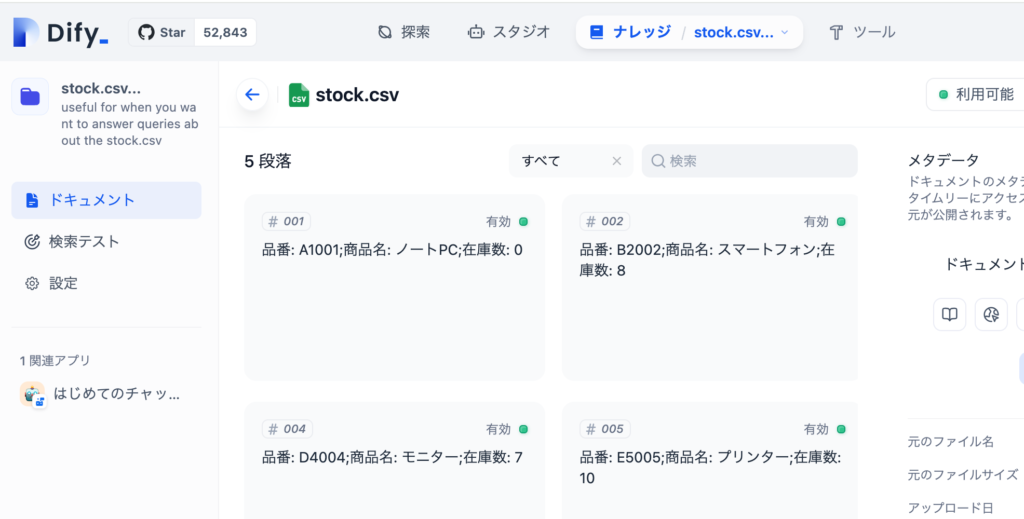
このようにナレッジAPIを利用することでDifyの画面を利用せずナレッジの情報にアクセスすることができます。
GAS(Google Apps Script)からのアップロード
curlコマンドを利用してファイルのアップロードを行いましたが、Google Sheetsに保存したスプレッドシートからGASを利用してデータを取得してファイルのアップロードを行うこともできます。
GASは以下の記事を参考にしていただければ基本的な利用方法を理解することができます。

Google Sheetsにアクセスを行いスプレッドシートのstockファイルを作成します。
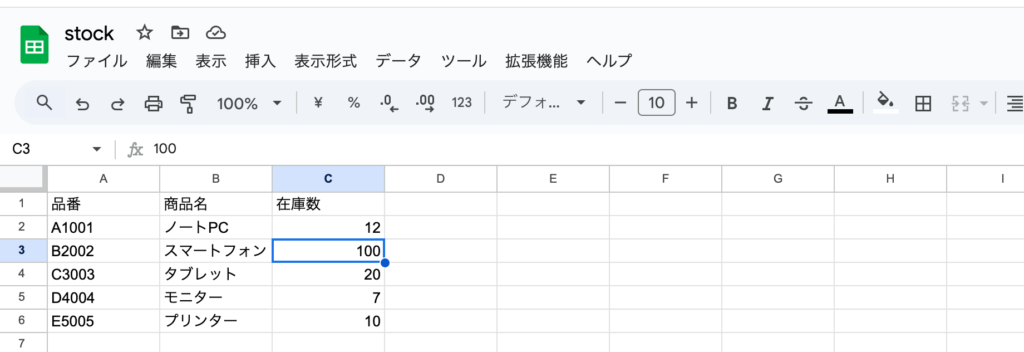
拡張機能からApps Scriptを作成します。
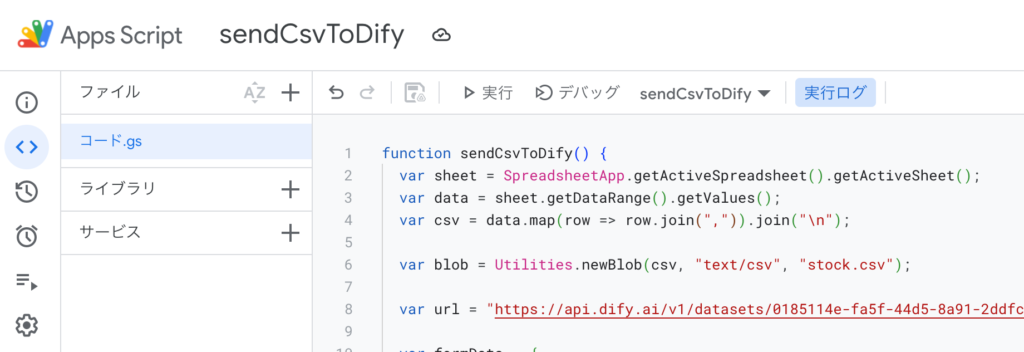
利用するコードは以下の通りです。
function sendCsvToDify() {
var sheet = SpreadsheetApp.getActiveSpreadsheet().getActiveSheet();
var data = sheet.getDataRange().getValues();
var csv = data.map(row => row.join(",")).join("\n");
var blob = Utilities.newBlob(csv, "text/csv", "stock.csv");
var url = "https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}update_by_file";
var formData = {
method: "post",
payload: {
file: blob
},
headers: {
"Authorization": "Bearer {your_knowledge_api}" // 必要に応じて認証情報を設定
},
muteHttpExceptions: true
};
try {
var response = UrlFetchApp.fetch(url, formData);
Logger.log("リクエスト成功: " + response.getContentText());
} catch (error) {
Logger.log("リクエスト失敗: " + error.message);
}
}
作成したスクリプトを実行することでGASを利用してDifyのナレッジを更新することができます。 Google Sheetsを更新して作成したスクリプトを実行することでいつでもDifyのナレッジを最新情報に更新することができます。
そのほかにもナレッジAPIを利用することで下記のことが可能です。
- データセットの作成
- データセットの削除
- テキストを通してドキュメントを作成/更新
- ファイルを通してドキュメントを作成
- ドキュメント埋め込みステータス(進捗状況)の取得
- ドキュメントの削除
- セグメントの追加
- セグメントの削除
- セグメントの更新