Difyのワークフロー徹底解説!入門者でもこれを読みばワークフローが作れる

Difyはプログラミングの知識がなくても業務に活用できるチャットボットが短時間で作成できる手軽さが魅力なアプリケーションです。私も試しにチャットボットを作成してみたところ、驚くほどスムーズに作成することができました。しかし、より高度なアプリを作成しようと「ワークフロー」からアプリを作成しようとすると設定や仕組みが思った以上に複雑でどこから手を付ければいいのかわからない状態に。Difyを使い始めた方の多くが、この「ワークフローの壁」に直面するのではないでしょうか。ワークフローの壁を越えて高度なアプリが作れるようにこの記事ではワークフローを使いこなすためのポイントや実践的なコツをわかりやすく解説しています。
Difyに興味があるけどまだ使ったことがないという人またはクラウドサービスのDifyのアカウントを作成していない人は最初に下記の公開済みの記事を一読することをお勧めします。Difyでチャットボットを作成する手軽さがわかります。

目次
ワークフローの作成
ワークフローの作成は、スタジオ(https://cloud.dify.ai/apps)画面の左側のメニュー”最初から作成”をクリックして表示されるモーダルウィンドウからワークフローを選択して行います。アプリには名前と説明を入力することができます。ここではワークフローの理解を深めるためにアプリを作成するので名前には”ワークフローの理解”、説明には”ワークフローの動作確認用のアプリ”と入力しておきます。
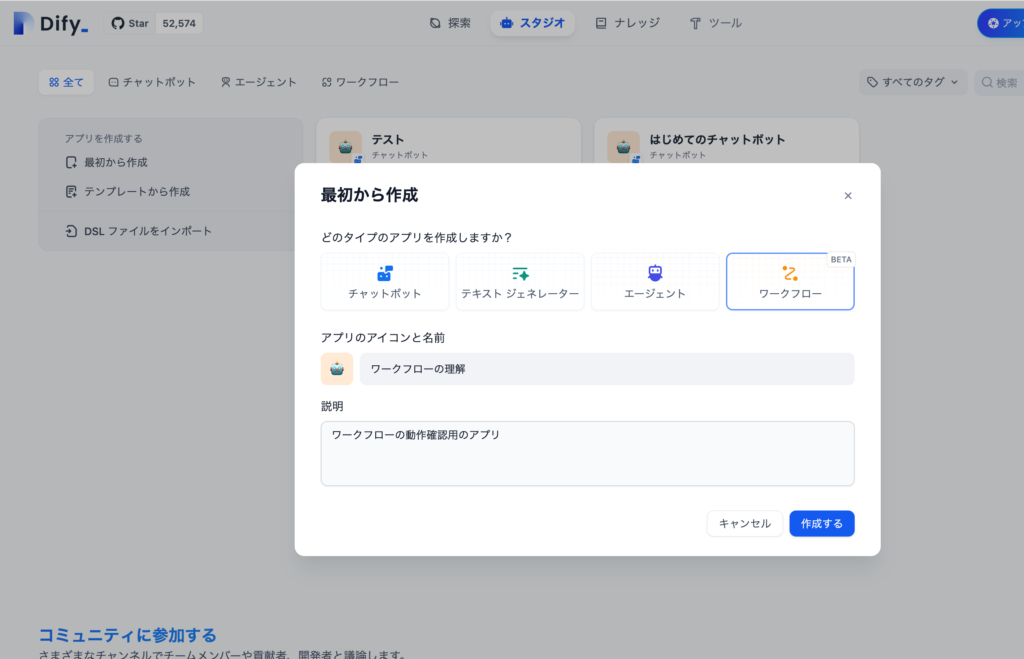
“作成する”ボタンをクリックするとオーケストレート画面が表示されます。初めての人の大半はこの時点で何をしたらいいかわからないと思いますので一つずつステップバイステップで説明していきます。
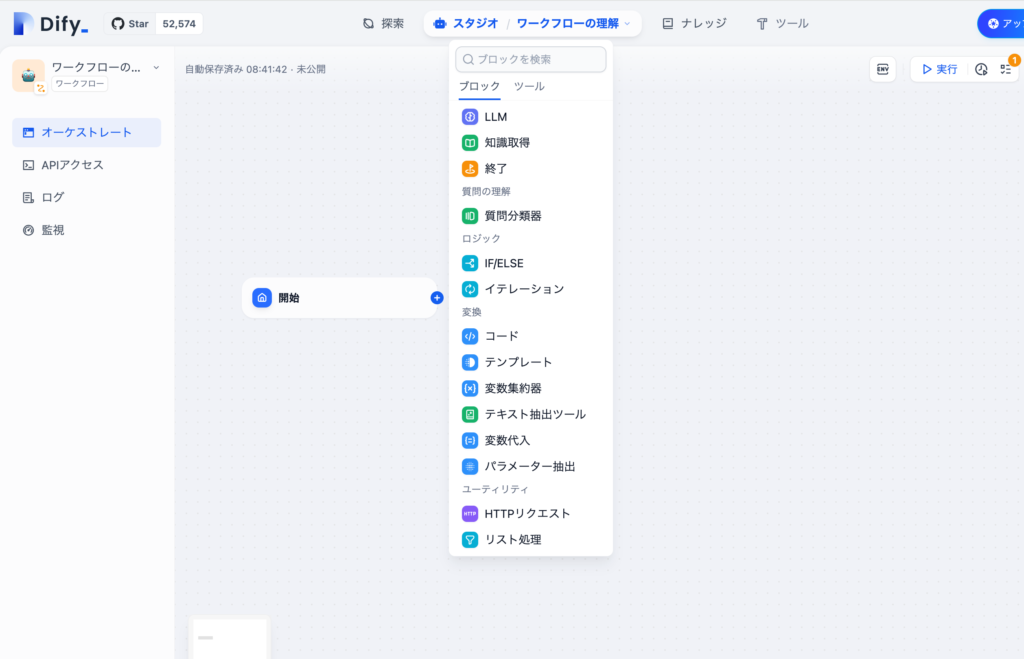
開始ってなに?
ワークフローではノードと呼ばれる独立したブロック要素をつなげていくことでアプリを作成していきます。ワークフローを作成した直後では開始ノードしか存在しません。開始ノードは必須のデフォルトノードで開始ノードを起点にアプリを作成していきます。開始ノード以外にも各ノードが存在しそれぞれのノードが特定の機能を持ち条件分岐やデータ処理などを担当します。
開始ノードをクリックすると右側に入力フィールドとシステム変数(sys.で始める変数)が表示されます。
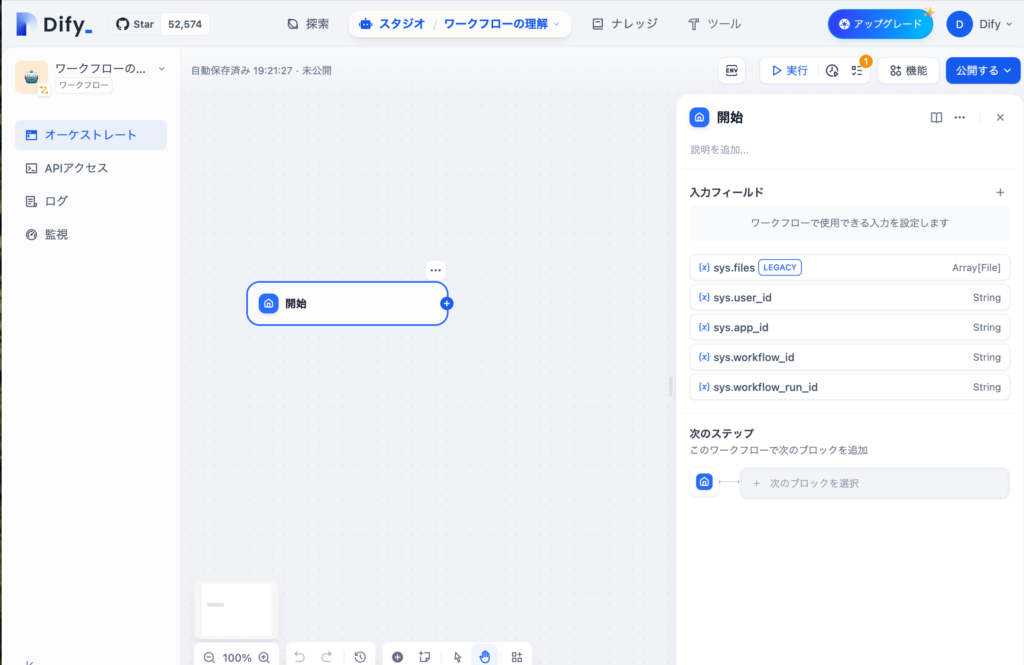
開始ノードの設定画面を開くと、sys.filesやsys.user_idといった sys で始まる変数が表示されます。これらはDifyのシステム変数で、システムが内部的に利用するために自動で設定されるパラメータです。ユーザーが手動で変更や設定を行う必要はありません。試しに [x] ボタンで削除を試みたくなるかもしれませんが、これらの変数はそのままにしておいて大丈夫です。後ほど必要に応じて自動的に値が設定されます。

入力フィールドをクリックすることでユーザが入力可能なフィールドを設定することができます。入力フィールドの”+”ボタンをクリックすると入力フィールドの追加のモーダルウィンドウが表示されます。フィールドタイプに短文、変数名、ラベル名にquestionを入れて”保存”ボタンをクリックします。入力が必須かどうかはチェックボックスで設定できます。
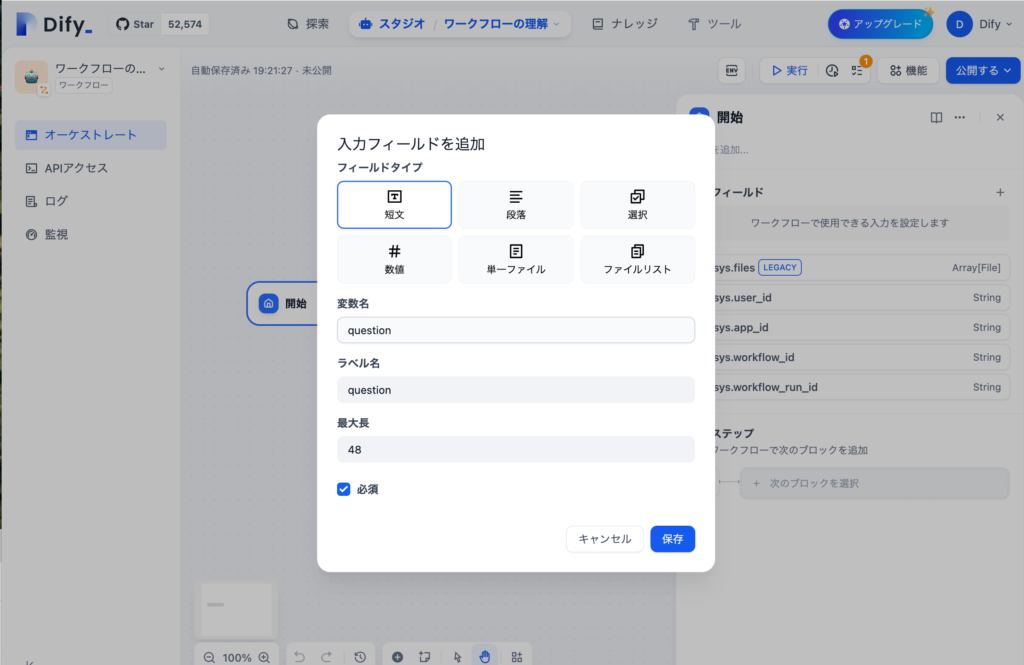
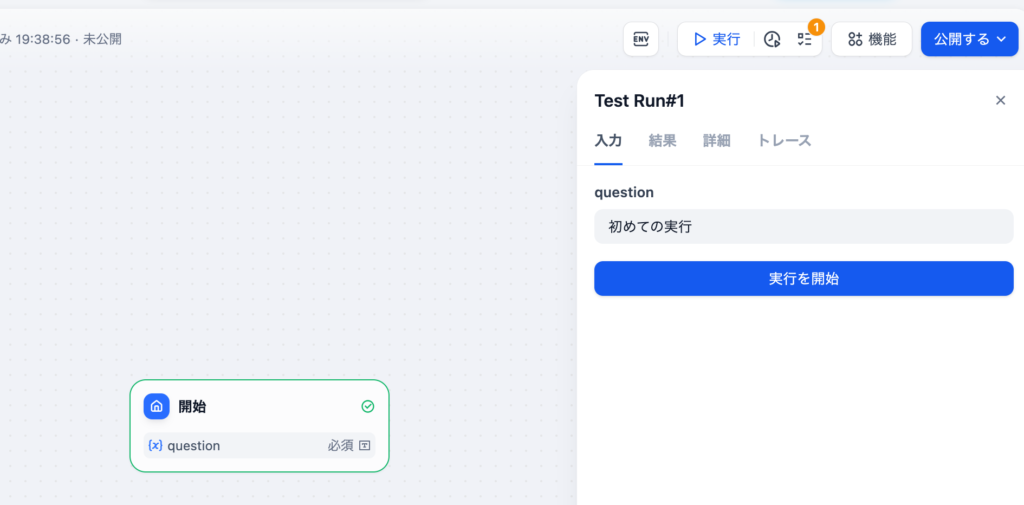
保存すると開始ノードに設定した変数名が表示されます。画面右上に表示されている”実行”をクリックすると設定した入力フィールドが表示され動作確認を行うことができます。試しにquestionフィールドに”初めての実行”を入力して”実行を開始”ボタンをクリックしてください。
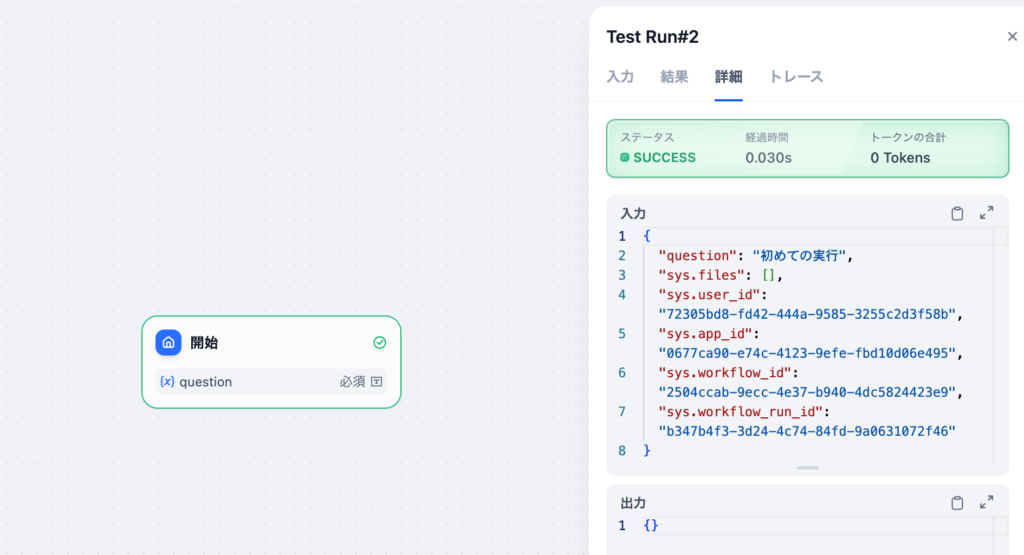
実行が完了すると詳細タブにJSON形式で入力した情報と自動で設定されたシステム変数の値が表示されます。sys.user_idなどシステムが自動で設定を行っていることがわかります。
フィールドタイプ
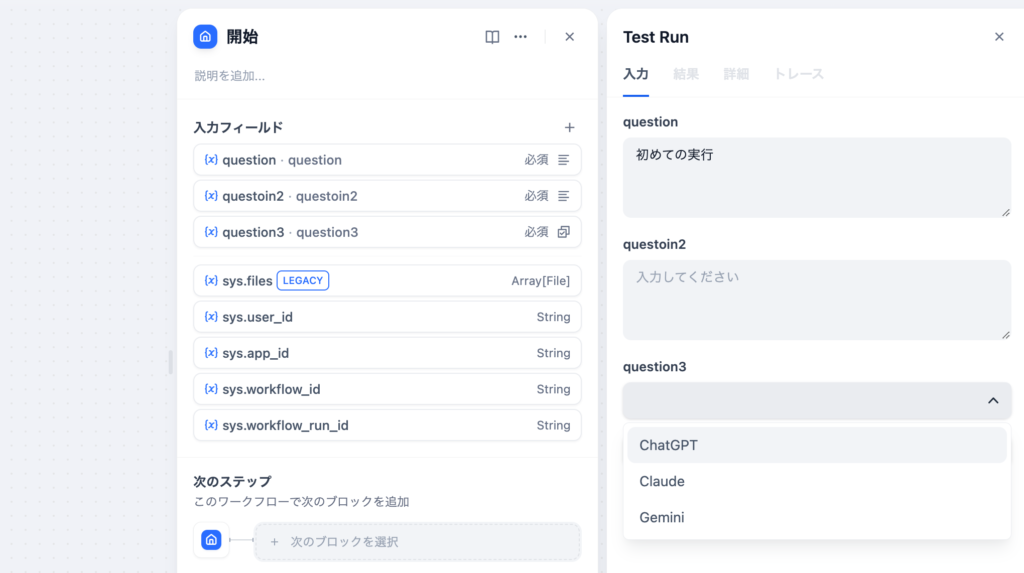
開始ノードでは複数の入力フィールドを設定することができるので短文、段落、選択のフィールドタイプ3つを開始ノードに追加後に”実行”を行うと設定した入力フィールドが表示されます。フィールドタイプの選択では選択項目をオプションで設定でき、ドロップダウンメニューで設定した項目を選択することができます。オプションにChatGPT, Claude, Geminiを設定しています。
開始ノードでは入力フィールドを設定することでユーザが入力するフィールドを設定できることがわかりました。
終了ノード
開始ノードは必須の項目でしたがアプリが終了する際に実行したい内容は終了ノードで設定することができます。
ここでは開始ノードで設定した変数の受け渡しを使って終了ノードを理解していきます。
開始ノードの”+”ボタンをクリックするとDifyで利用できるブロックが表示されます。その中なら終了ブロックを選択します。
終了ノードが作成されると開始と終了ノードが線で接続され、順番に処理が行われます。終了ノードでは出力変数を設定することができます。
出力変数では開始ノードで設定した変数を設定することができます。
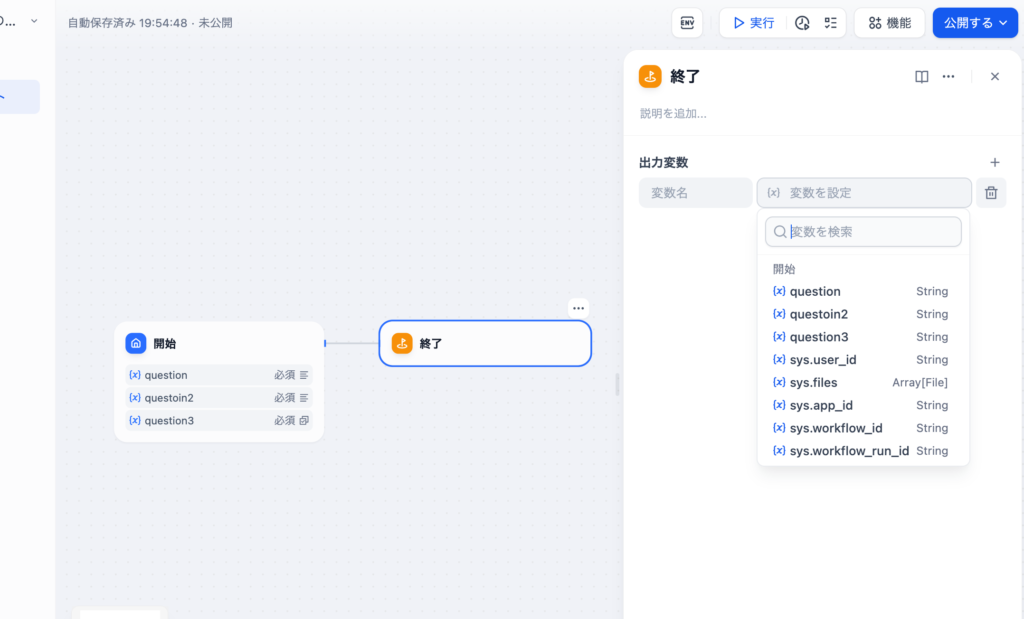
ドロップダウンで表示されている入力フィールドの変数をすべて選択すると下記のように表示されます。
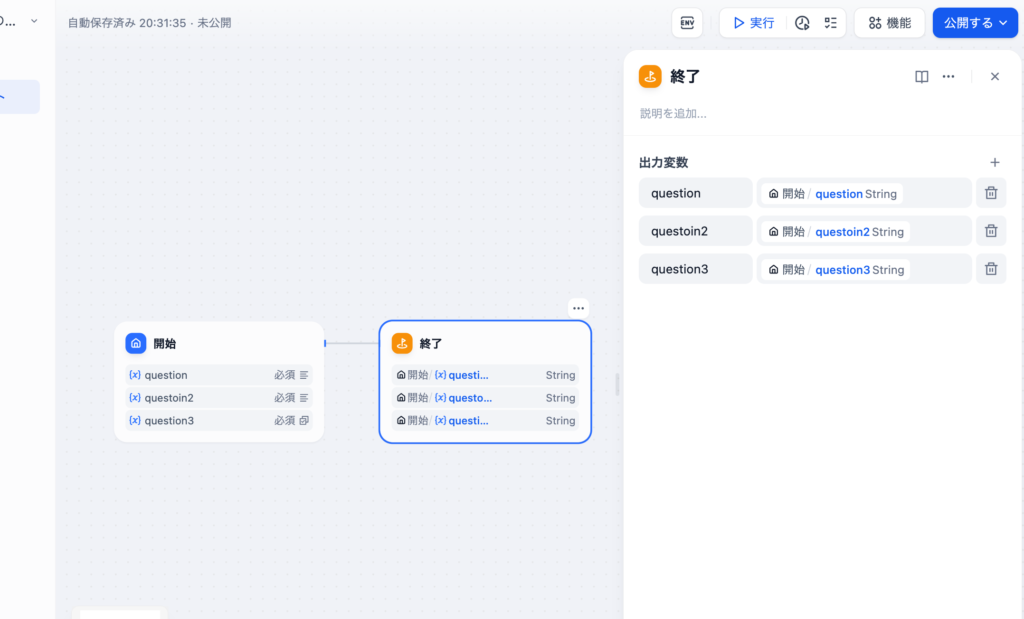
開始ノードと終了ノードを設定したら実行で動作確認を行います。入力フィールドに任意の値を入力して”実行開始”ボタンをクリックします。
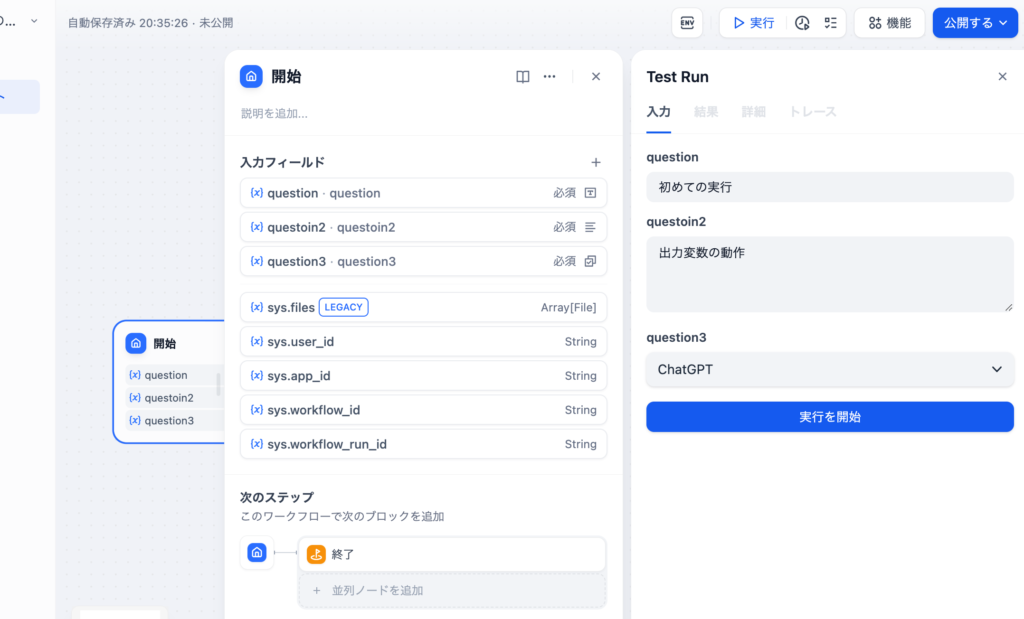
開始ノードのみを設定した時の詳細タブの内容とは異なり、入力だけではなく出力も表示されていることがわかります。開始ノードで設定した変数の値が終了ノードで正しく出力されていることが確認できます。
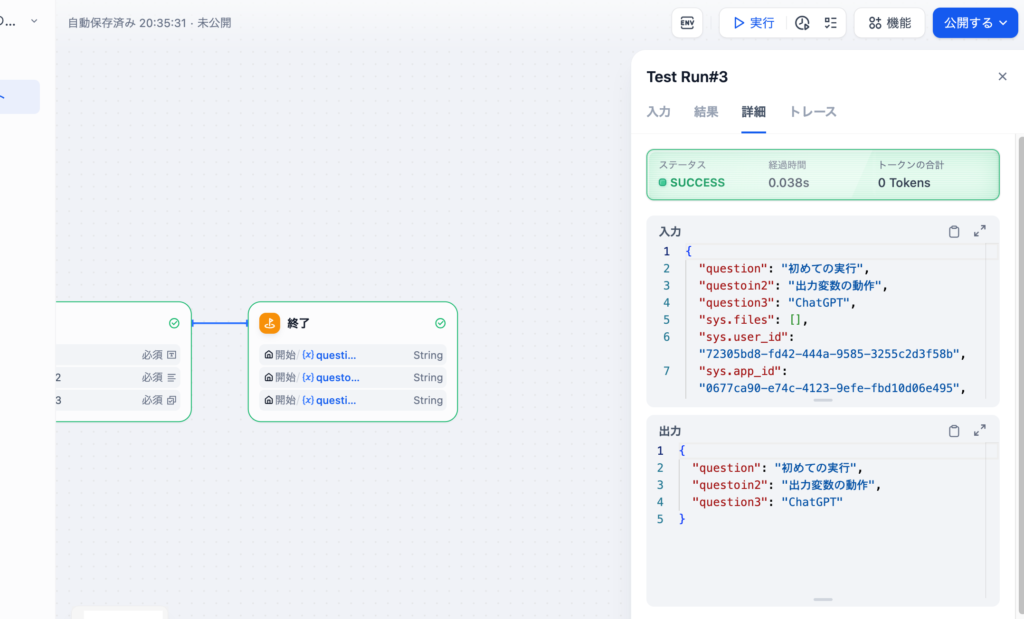
ここまでの動作確認で開始ノードではユーザの入力フィールド、終了フィールドではアプリ内で定義した変数を出力変数として出力できることがわかりました。
アプリの公開
ここまでの設定でアプリの公開を行うとどのようなアプリ画面が表示されるのか確認していみましょう。右側の公開するボタンを利用してアプリの公開を行います。
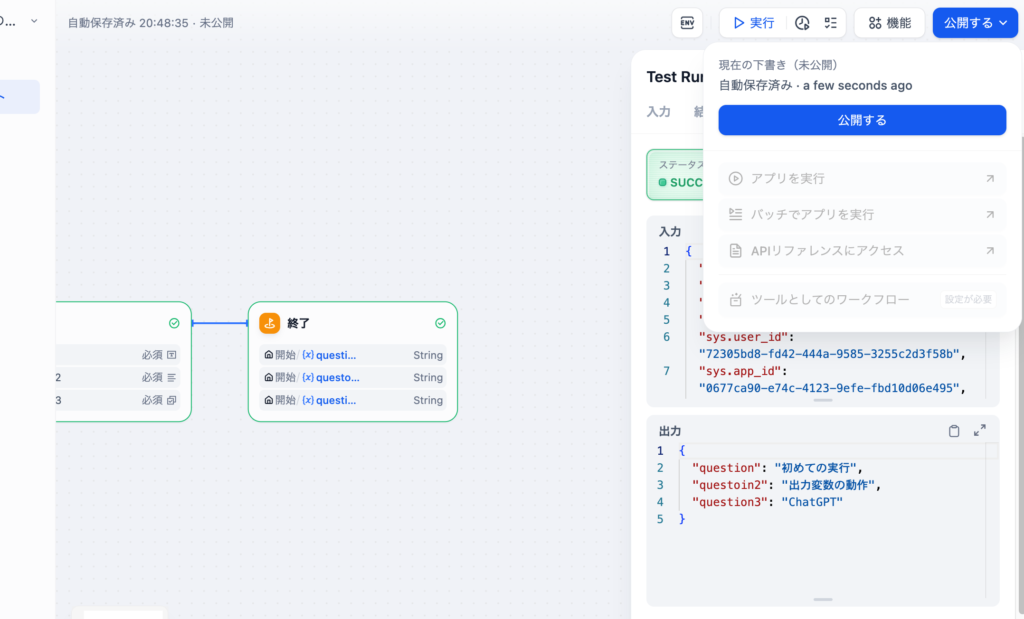
“公開する”ボタンをクリックすると”アプリを実行が”クリックできるようになるのでクリックすると下記のアプリ画面が表示されます。任意の値を入力して実行すると実行結果が右側に表示されます。
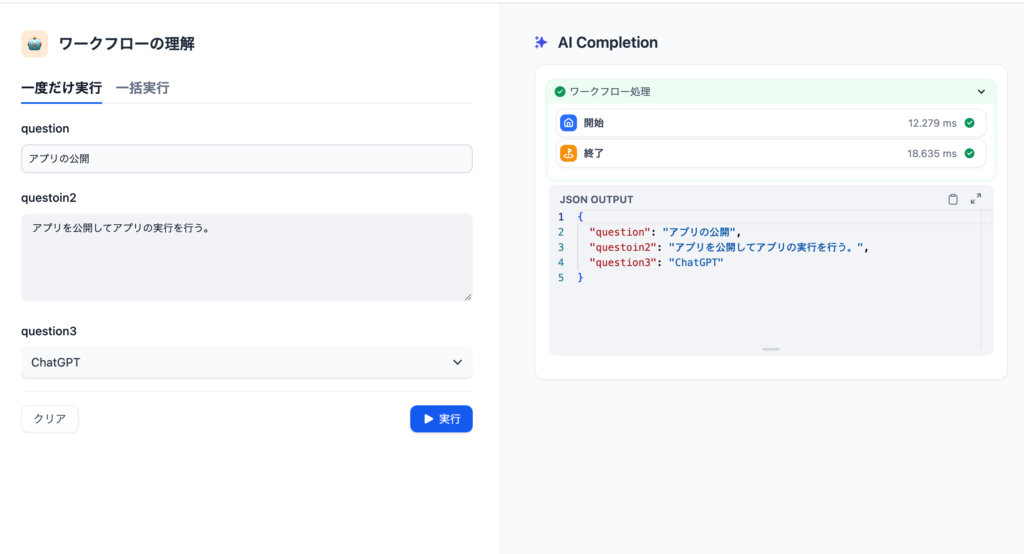
チャットフローとワークフローの違い
”アプリを作成する”のメニューの”最初から作成”ボタンをクリック後に表示される画面でチャットボットを選択するとチャットフローを選択することができます。
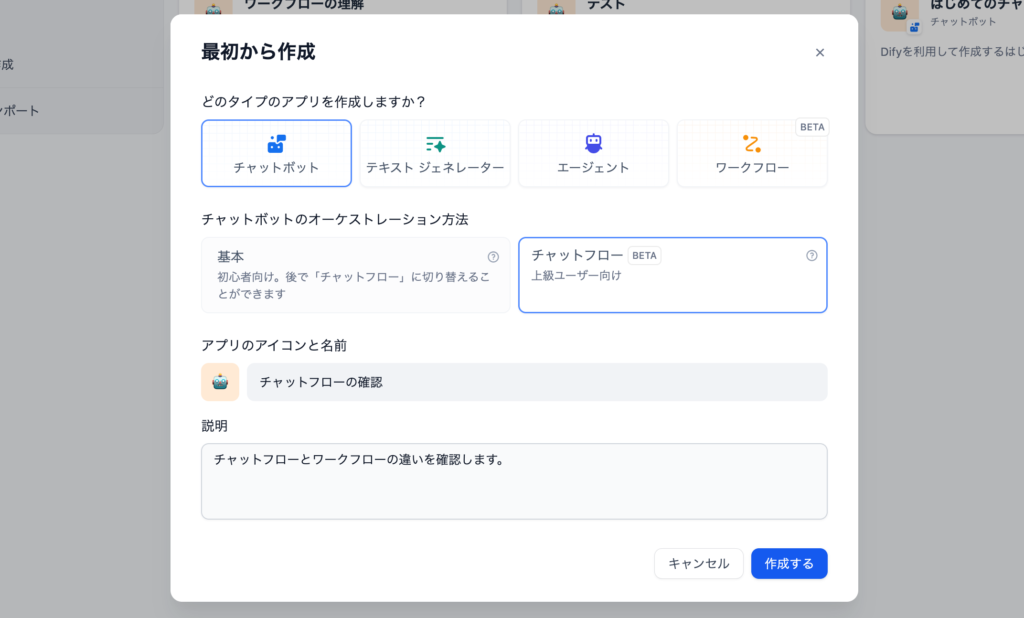
ワークフローからチャットフローを作成できるのではないかと思う方もいるかもしれません。しかし、チャットフローとワークフローでは開始ノードで使用されるシステム変数が異なるため、直接的にワークフローをチャットフローとして利用することはできません。例えば、チャットフローの開始ノードでは主にユーザーからの入力を扱うためのシステム変数がデフォルトから設定されていますが、ワークフローの開始ノードはデフォルトでは設定されておらず必要に応じて設定を行います。この違いを理解して、それぞれのフローを適切に選択して作成してください。実際にチャットフローを確認してみましょう。
チャットフローの作成は”最初から作成”画面でチャットボットを選択してオーケストレーション方法で”チャットフロー”を選択します。
チャットフローの場合は作成した直後に3つのノードでフローが設定された状態で、開始ノードしか存在しないワークフローとは異なります。system変数にsys.query, sys.filesなどが追加されており、開始ノードでユーザの入力フィールドを設定する必要がありせん。
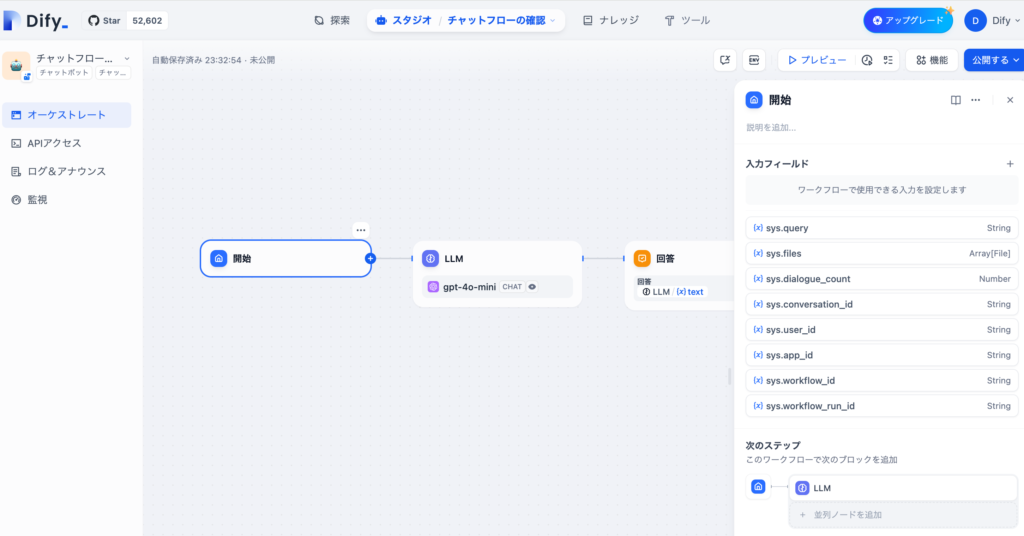
ワークフローの場合は”実行”のボタンもチャットフローでは”プレビュー”ボタンとなり、動作確認を行う際のインターフェイスも異なります。
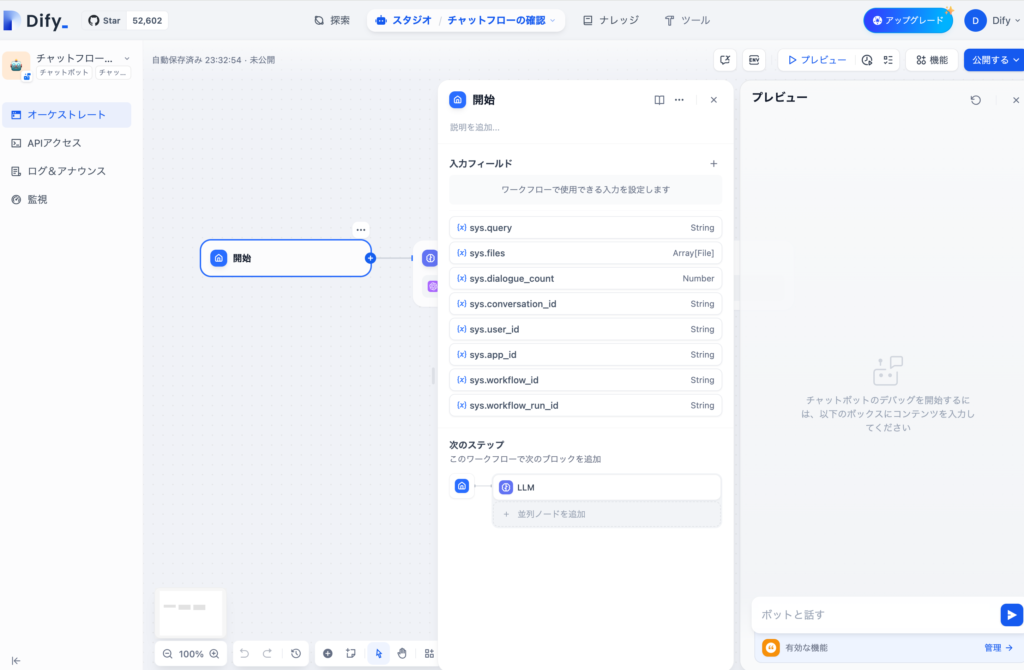
チャットフローはワークフローと同様にノードを利用してフローの設定を細かく行うことができますがチャット専用のアプリを作成するためのものであることがわかります。
FAQワークフローを作成してみよう
開始ノードと終了ノード、変数の理解が進んだので、ユーザが質問を行うと回答が戻されるアプリをワークフローを利用して作成していきます。ここではECサイトのFAQを想定しています。
ECサイトを運用している場合には自社独自の送料、キャンセルの条件などがあるため生成AIが持っていない情報を事前に与えておく必要があります。Difyではナレッジを利用して情報を追加します。
ナレッジの作成
ナレッジを作成する前にナレッジに登録する情報を準備する必要があります。
今回利用するFAQ一覧はChatGPTを利用して作成していますが通常は自社のFAQを登録することになります。Question, Answerの2列から構成され、コンマで区切られているCSVファイルを利用します。名前はEC_Site_FAQ.csvです。

上部のメニューからナレッジをクリックするとナレッジを作成するボタンと登録済みのナレッジが表示されます。
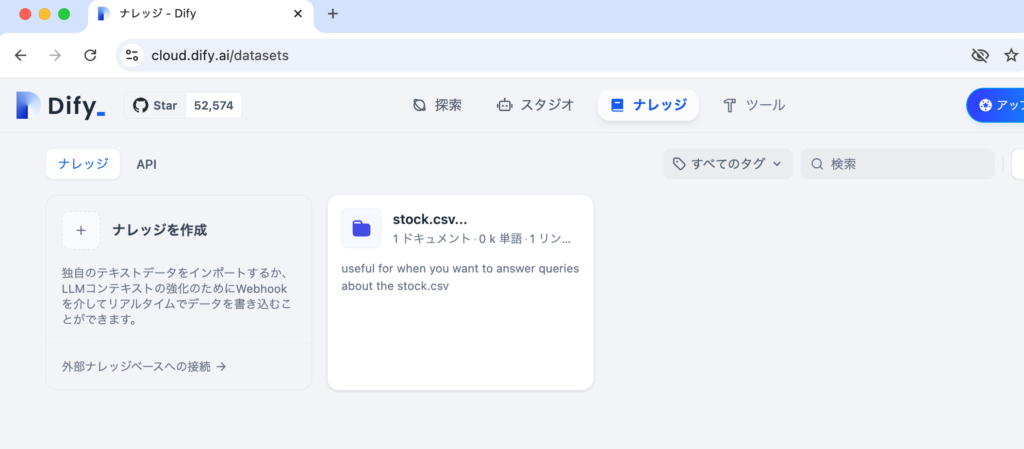
”ナレッジを作成する”をクリックするとデータソースの選択画面が表示されるので用意したCSVファイルをアップロードします。アップロードが完了したら”次へ”ボタンをクリックします。
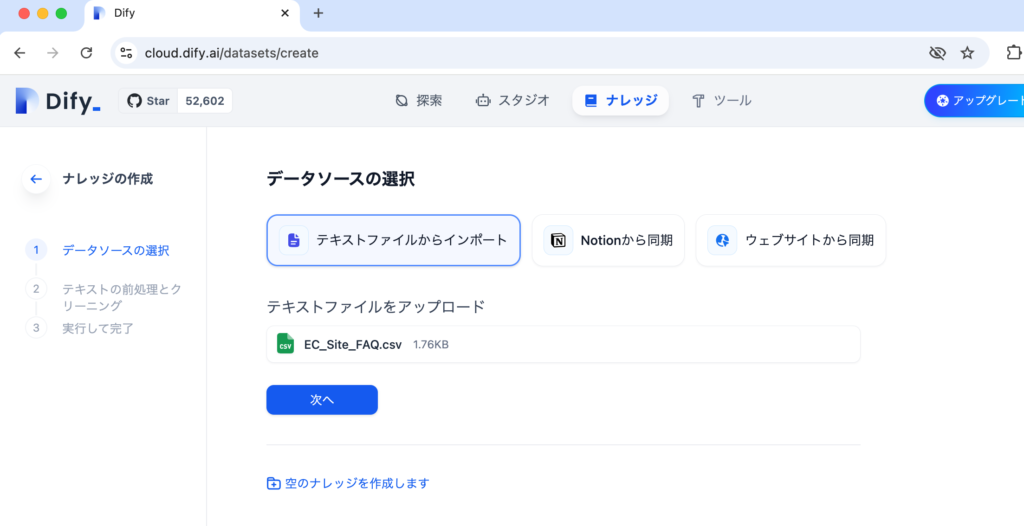
インデックスモードを高品質にすると精度が上がりますがここでは”経済的”でも動作するのか確認するために”経済的”を選択しています。経済的とは異なり高品質を選択するとLLMのTokensを消費することになります。設定が完了したら”保存して処理”ボタンをクリックします。
これでナレッジへの登録は完了です。
知識取得ブロックの設定
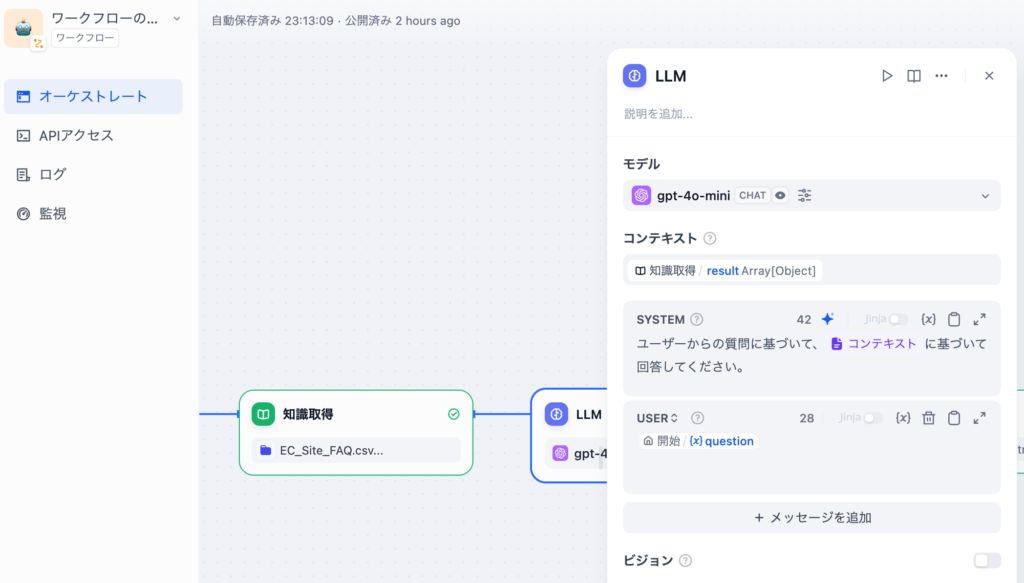
ナレッジの作成が完了したので作成したナレッジを設定するため開始ノードと終了ノードを繋ぐ線上の”+”ボタンをクリックします。開始ノードと終了ノードの間に新たに知識取得ノードを追加することができます。
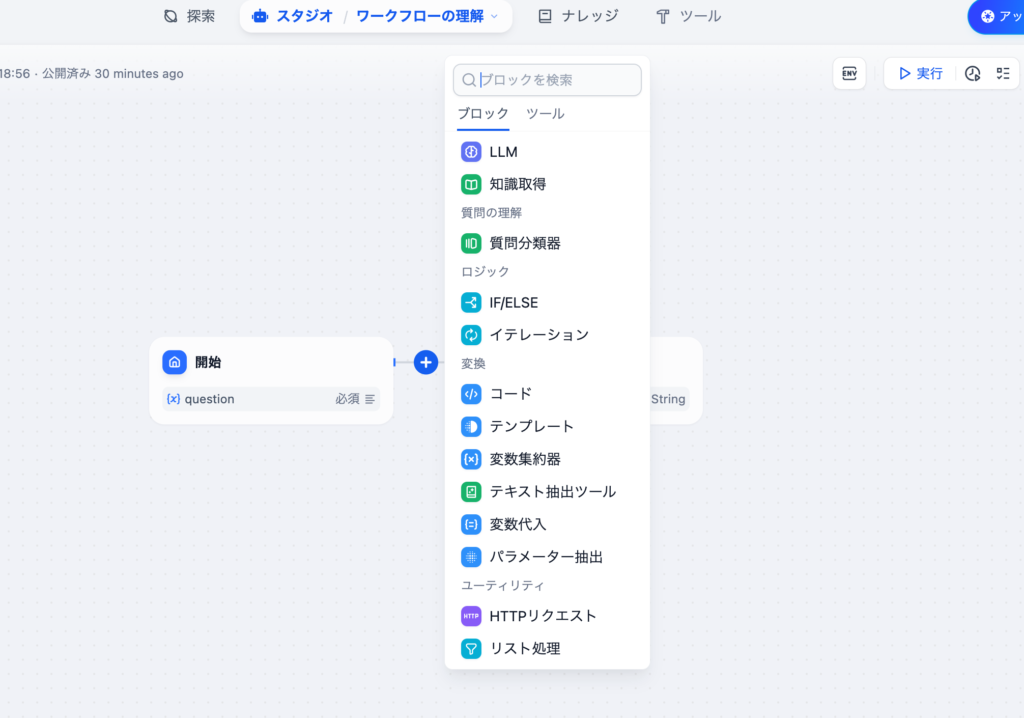
知識取得ではクエリ変数、ナレッジを設定することができます。
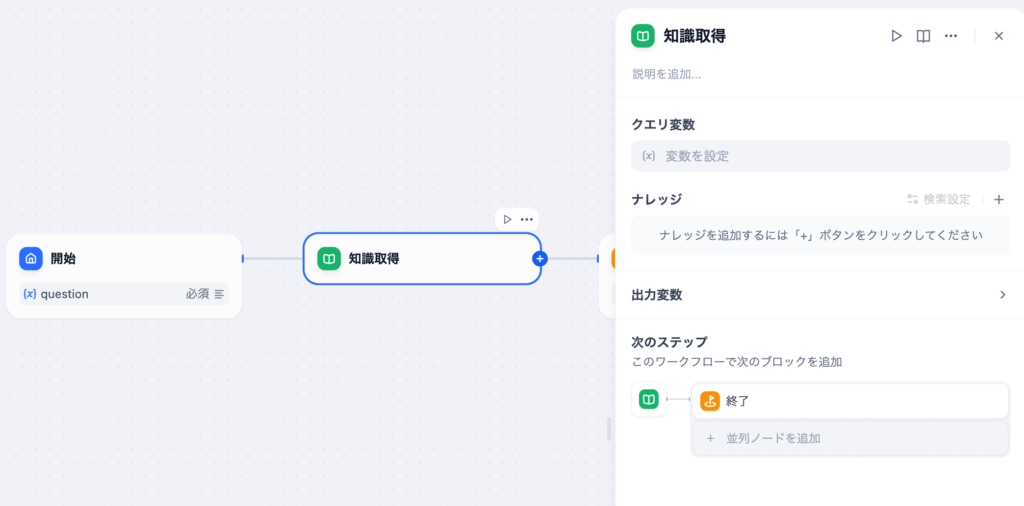
クエリ変数はナレッジから情報を取得する際に利用する変数でここでは開始ノードでユーザが入力したquestion変数を設定します。ナレッジの設定箇所では登録したFAQの情報を利用します。出力変数を開くと知識取得処理後のデータにどのような値が含まれているか確認できます。
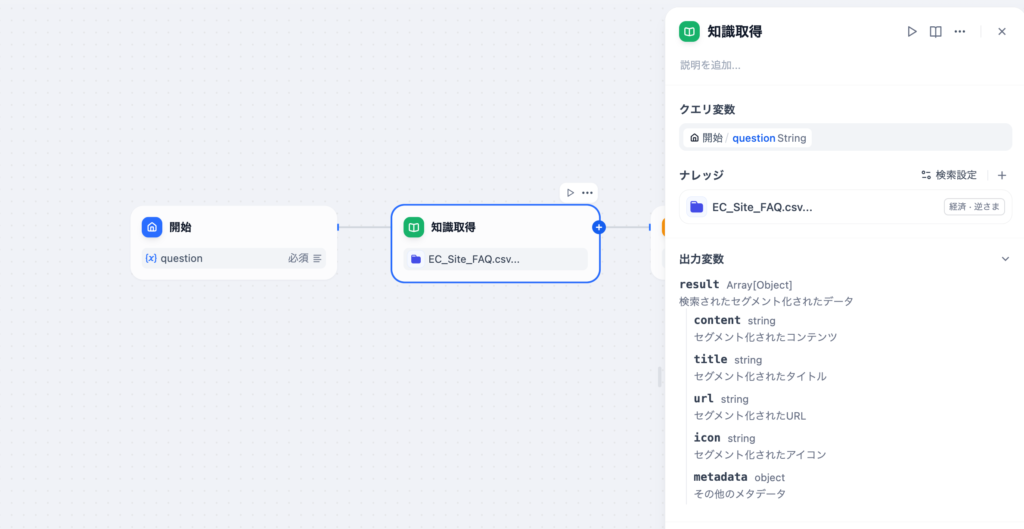
知識取得の設定が完了したら知識取得でどのような情報が取得できるのか確認するために終了ノードの出力変数に知識取得の出力変数resultを設定します。
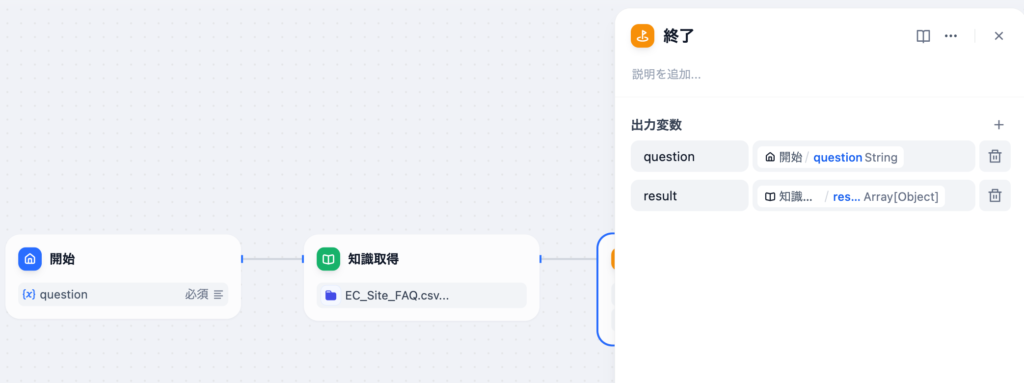
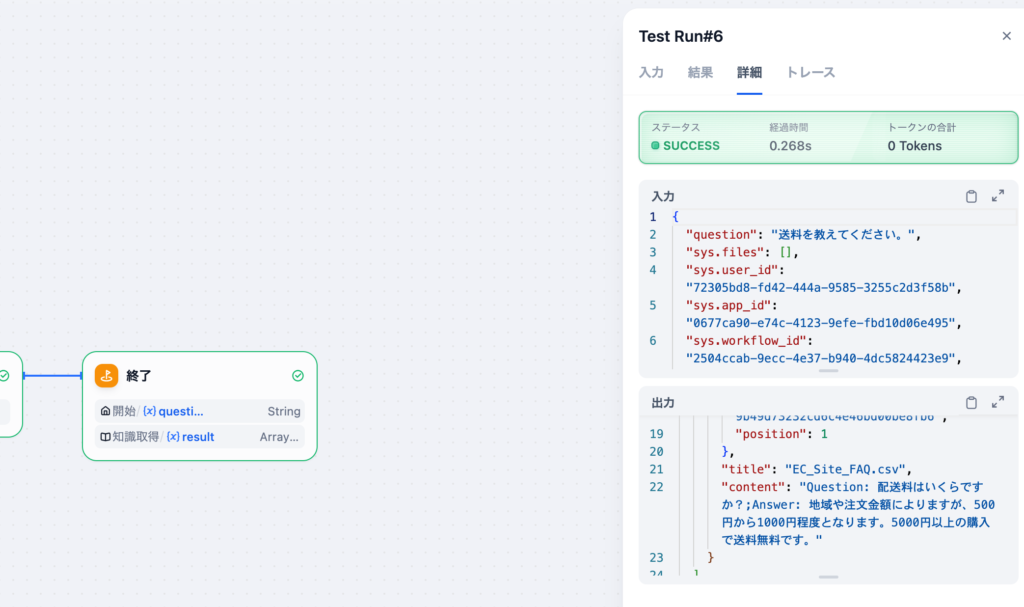
設定後、実行で動作確認を行います。入力フィールドには”送料を教えてください。”を入力しました。実行した結果、ナレッジから配送料に関するQ&Aが取得できていることがわかります。
ナレッジに含まれていない情報を入力するとresultは空となります。
LLMブロックの設定
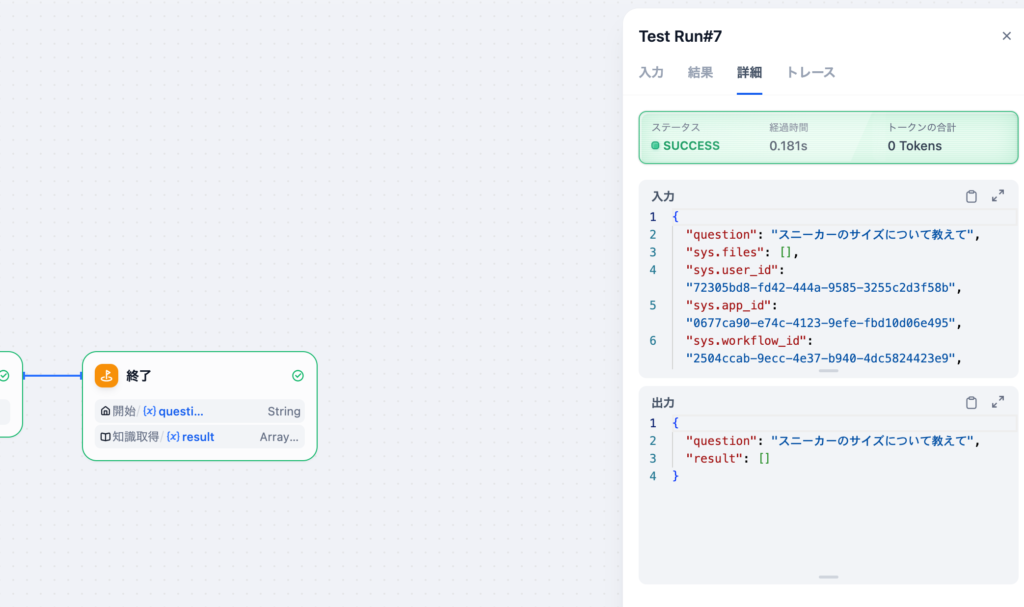
知識取得で得られた情報を大規模言語モデル(LLM)に渡すため知識取得と終了ノードを繋ぐライン上の”+”ボタンをクリックしてLLMをクリックします。
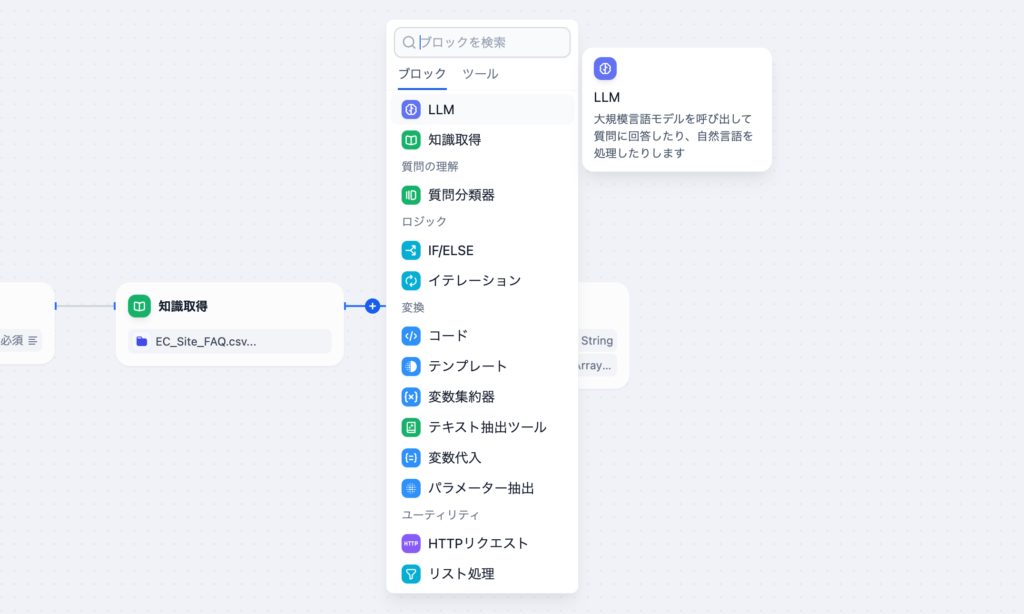
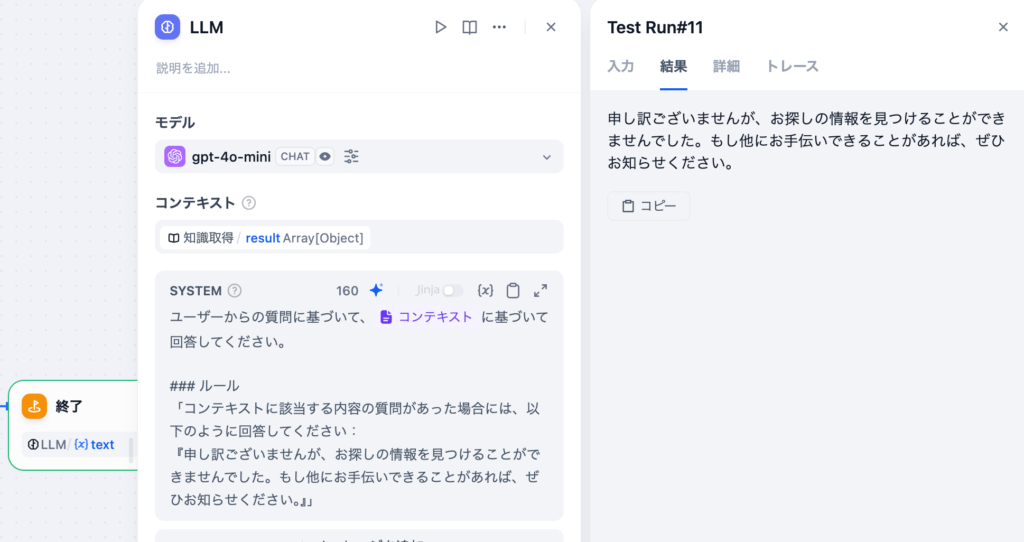
LLMブロックではモデルとコンテキストを設定することができます。LLMの処理が完了すると出力変数としてtextを利用することができます。text変数の中にLLMからの回答が含まれています。
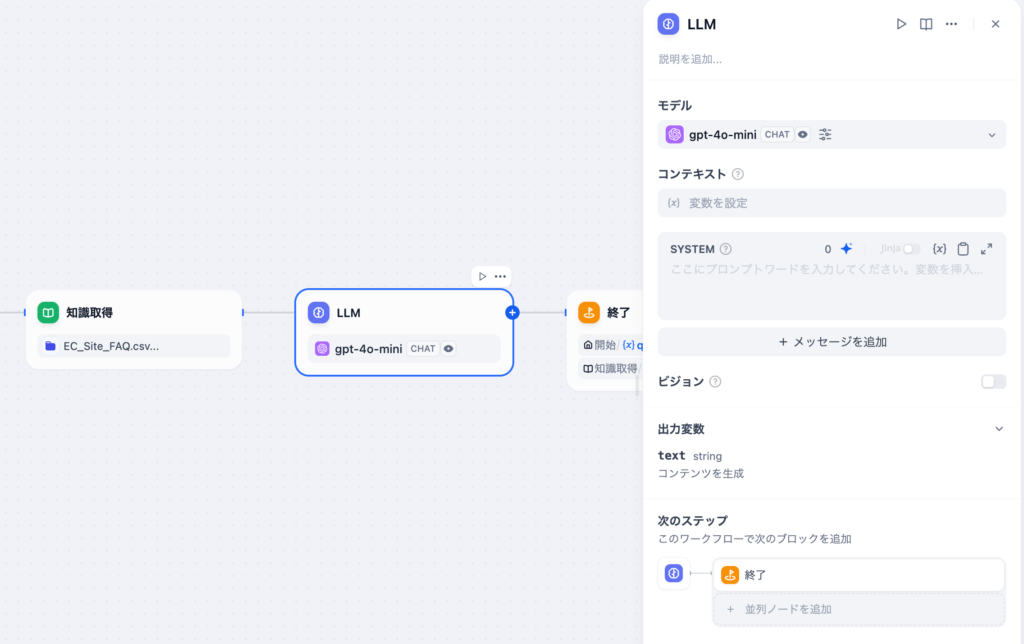
モデルはここではgpt-4o-miniを設定しています。プルダウンメニューからモデルの変更は可能です。コンテキストに知識取得の結果のresultを選択します。選択すると”コンテキスト機能を有効にするためには、PROMPTにコンテキスト変数”を記入してください。”と表示されます。LLMはコンテキストを利用して回答を作成するのでプロンプトにコンテキスト変数を入れることが必須です。プロンプトは下部のSYSTEMに入力します。
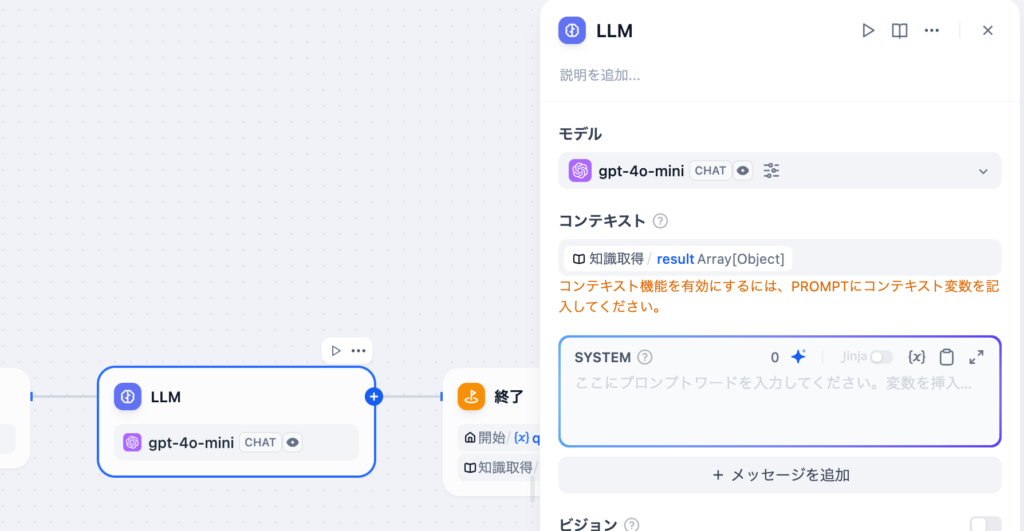
SYSTEMプロンプトにコンテキストを追加する際には挿入したい場所にカーソルを合わせて(x)を押すことで選択することができます。
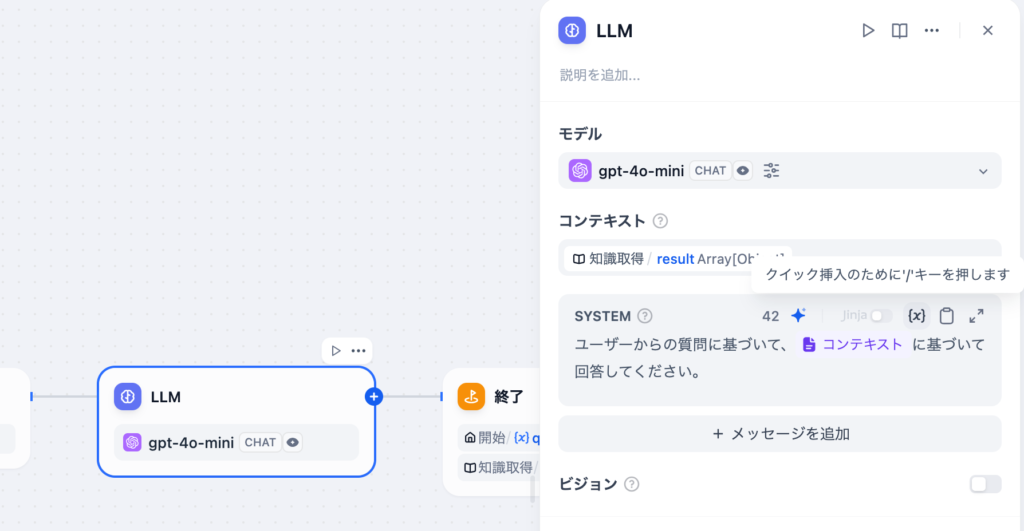
LLMの設定が完了したら、終了ノードでLLMの出力変数であるtextを選択します。
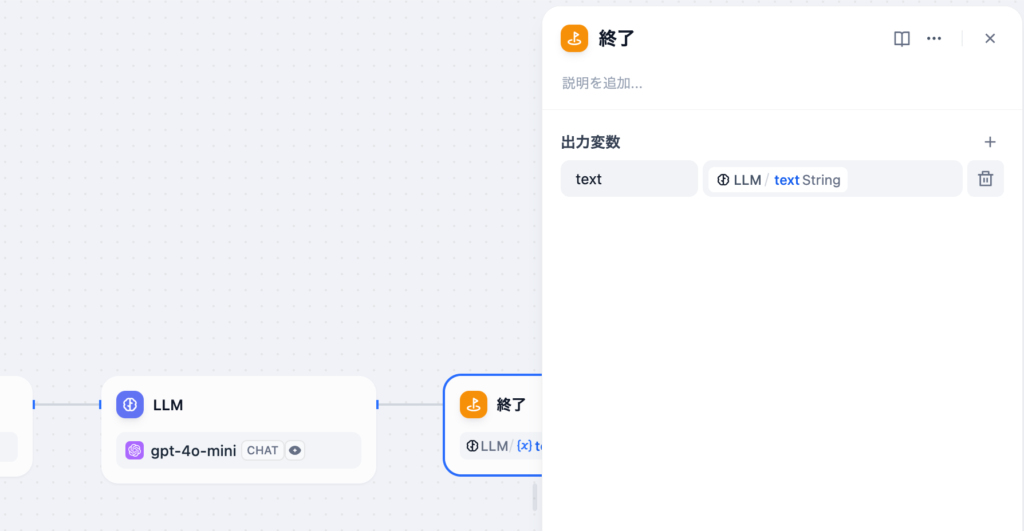
実行による動作確認
実行ボタンをクリックして入力フィールドのquestionに”送料について教えてください。”と入力して”実行を開始”ボタンをクリックします。
結果にはLLMを通して作成された回答が表示されます。
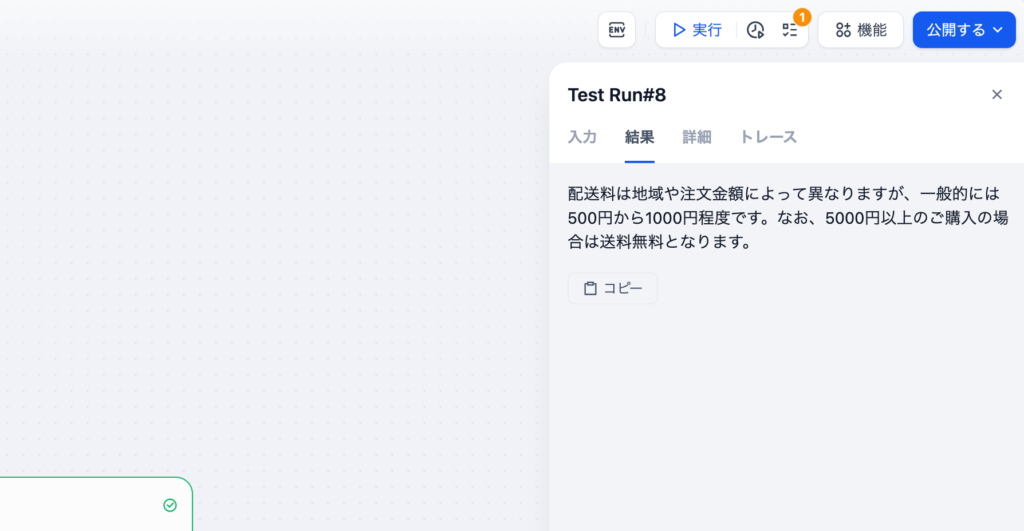
結果ではLLMから戻されてきた回答のみ表示されていますが、トレースのデータ処理を確認することでLLMにどのような情報が送信されているかも確認することができます。また利用したTokensの数も確認できます。今回は110tokensです。
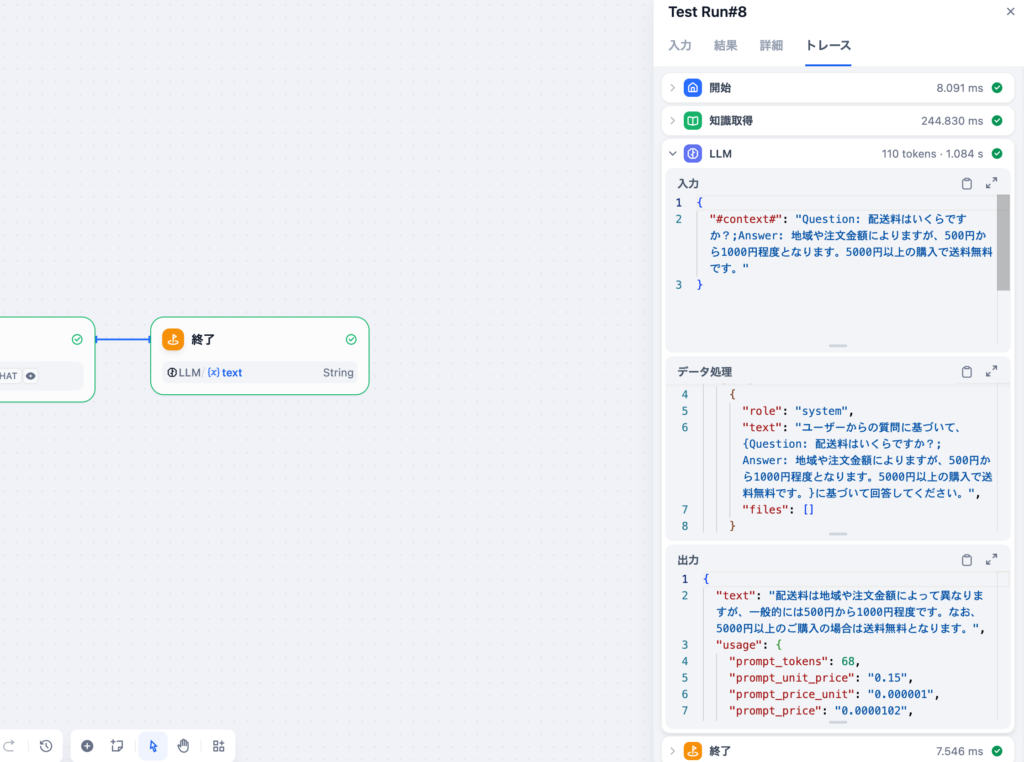
“スニーカーのサイズについて教えて”と入力すると知識取得から何も情報が得られないので下記の回答となります。
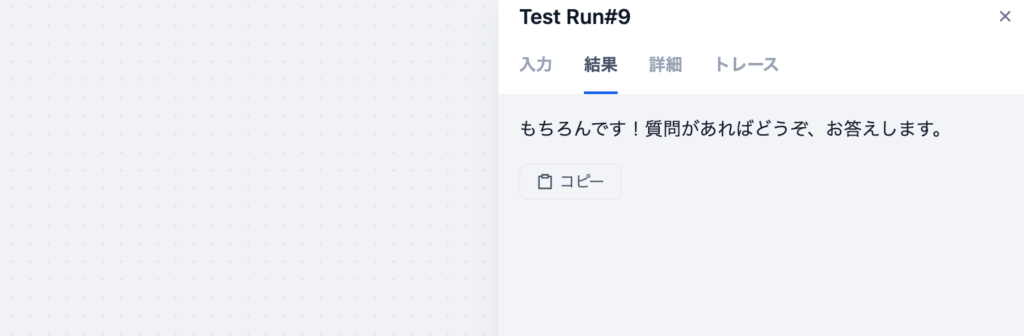
プロンプトが問題ないので以下のような文章をSYSTEMプロンプトに追加することで結果で戻される内容が変わります。
プロンプトではSYSTEMプロンプトだけではなくUSERプロンプトも設定することができ、LLMにユーザが質問した内容を一緒に渡すこともできます。USERからの入力した情報を追加しLLMに送信することで回答の質を高めることができます。プロンプトを調整しながらLLMから適切な回答を出してもらうように設定することができます。
FAQのアプリの作成を通して知識取得、LLMの設定を行うことでどのようなデータがそれぞれの処理で作成、利用、送信されていることが理解できました。
その他のブロック
その他のブロックについても動作確認を行いながら理解を深めていきます。
IF/ELSEブロック
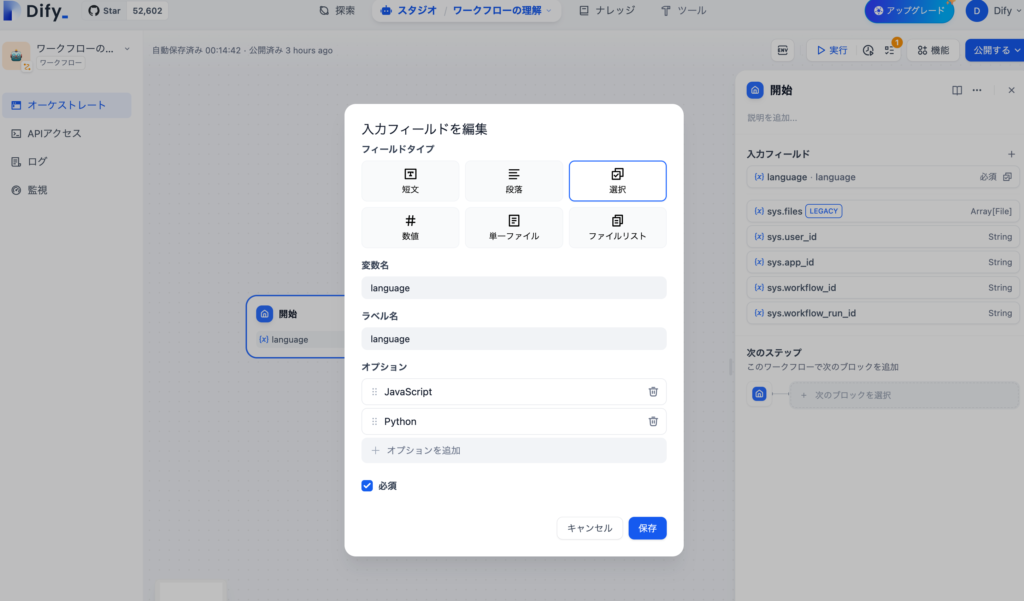
if/elseの条件を設定することでワークフローを分岐することができます。開始ノードの入力フィールドでフィールドタイプを”選択”に設定してオプションにPythonとJavaScriptを選択できるようにします。変数名にはlanguageを設定しています。
開始ノードの”+”ボタンをクリックしてロジックカテゴリーにあるIF/ELSEブロックを選択します。
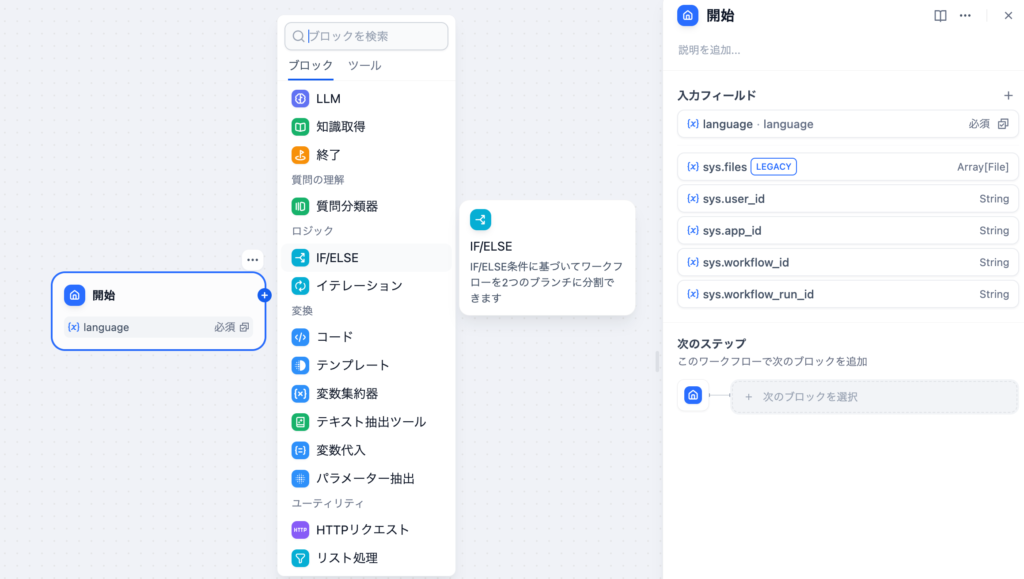
IF/ELSEノードの設定ではIFの条件を設定します。ここでは開始ノードで設定したlanguage変数を使って分岐させます。変数の中に値が含む、含まない、空などの条件を設定することができます。
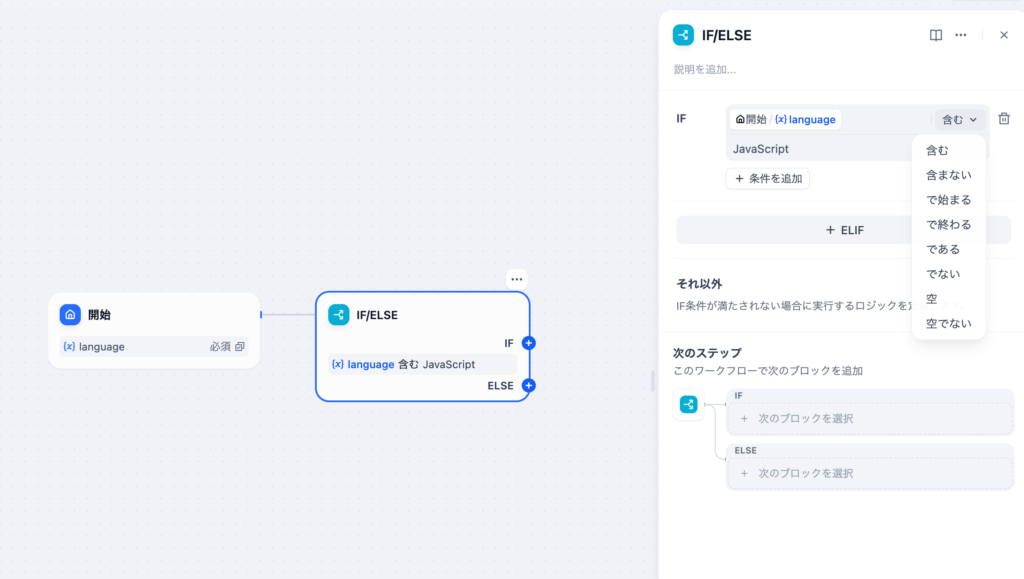
条件がtrueの場合はIF/ELSEノードのIFの”+”側のフローに進み、falseの場合はELSEの”+”側のフローに進みます。条件分岐は一つではなく複数設定(ifelse)することができ、分岐の分だけフローが枝分かれしていきます。
テンプレートブロック
テンプレートブロックではテンプレートに変数を埋め込むことができます。IF/ELSEの分岐後にテンプレオートブロックを追加します。
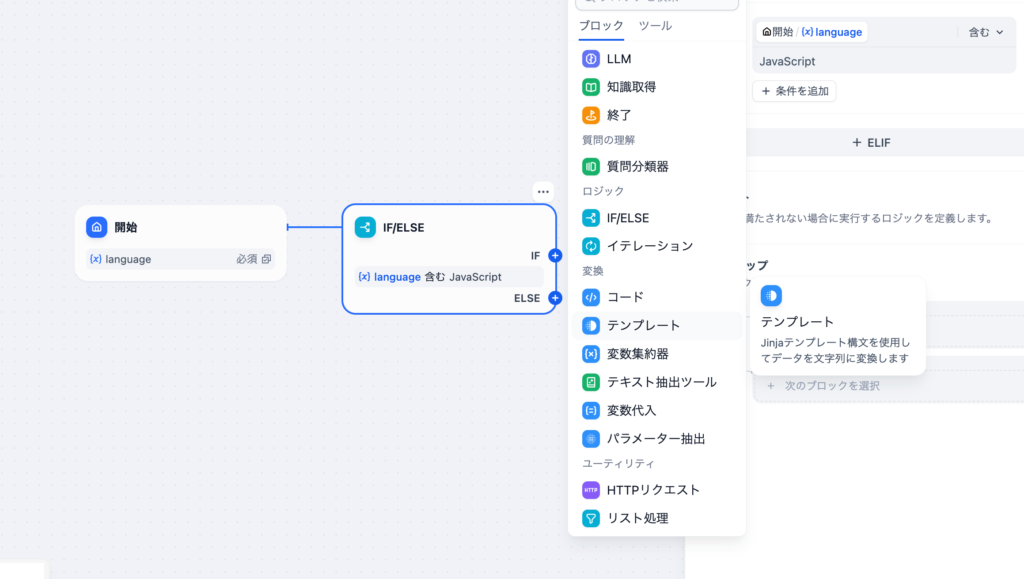
テンプレートブロックでは変数を入力変数として受け取ることができます。
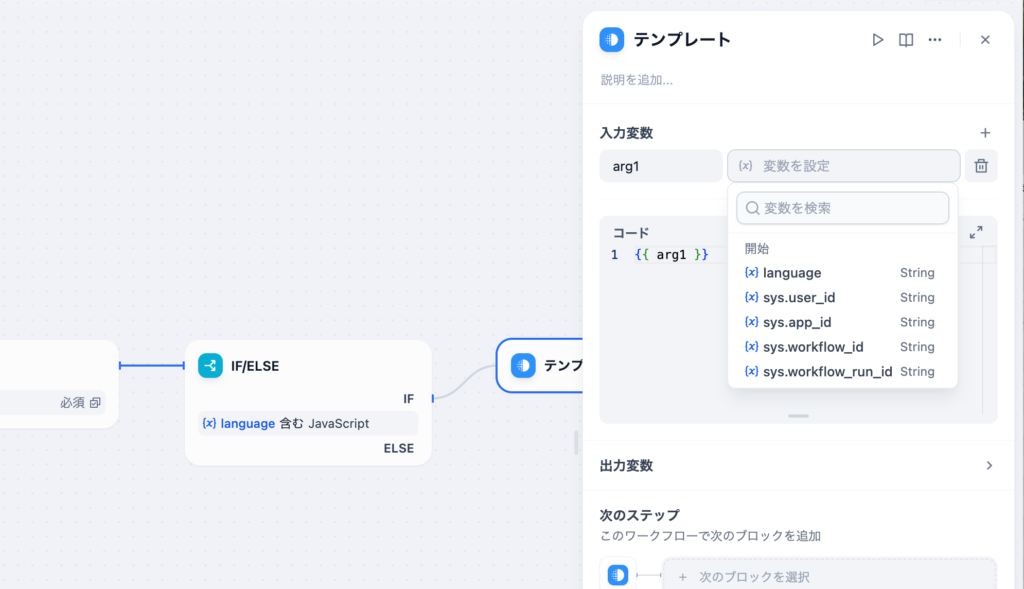
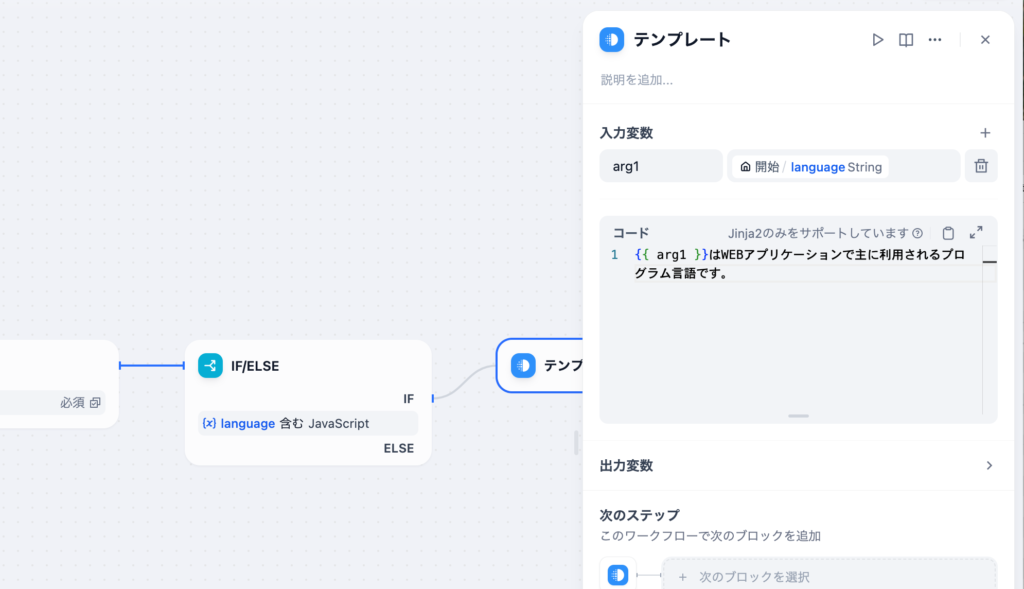
入力変数にlanguageを設定してコードを更新して文字列を追加します。arg1にlanguageの値が入ります。
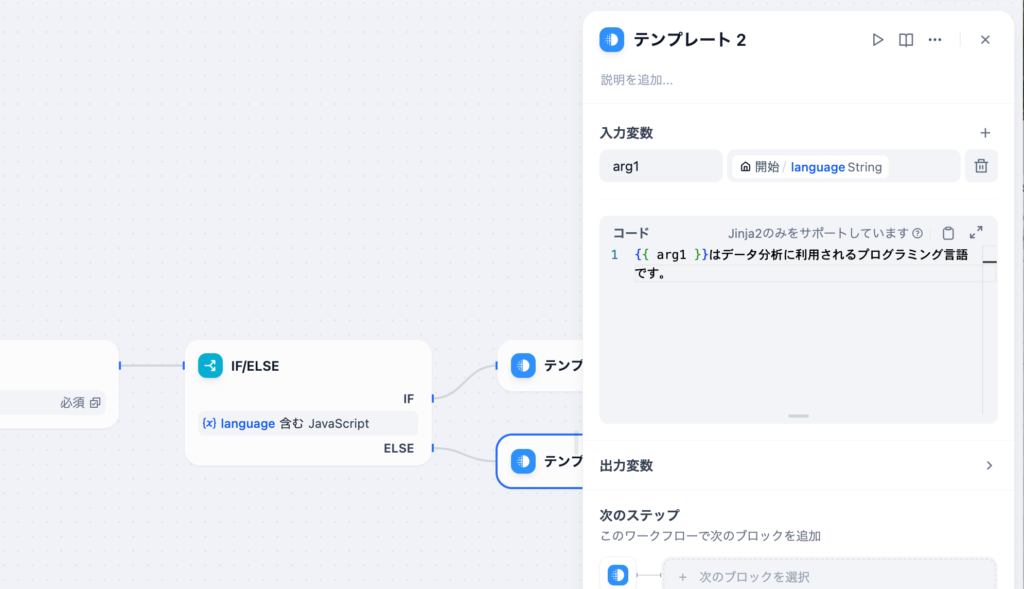
ELSEの場合のテンプレートも作成します。設定方法は先ほどと同じです。
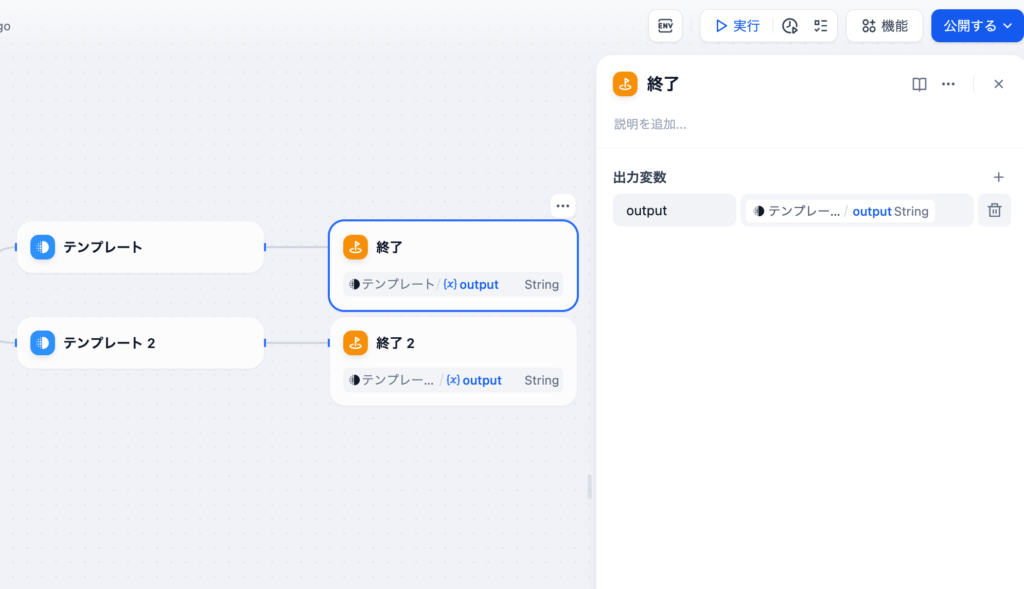
両方のテンプレートの後に終了ノードを設定することもできます。終了ノードではテンプレートのoutputを出力変数に設定します。
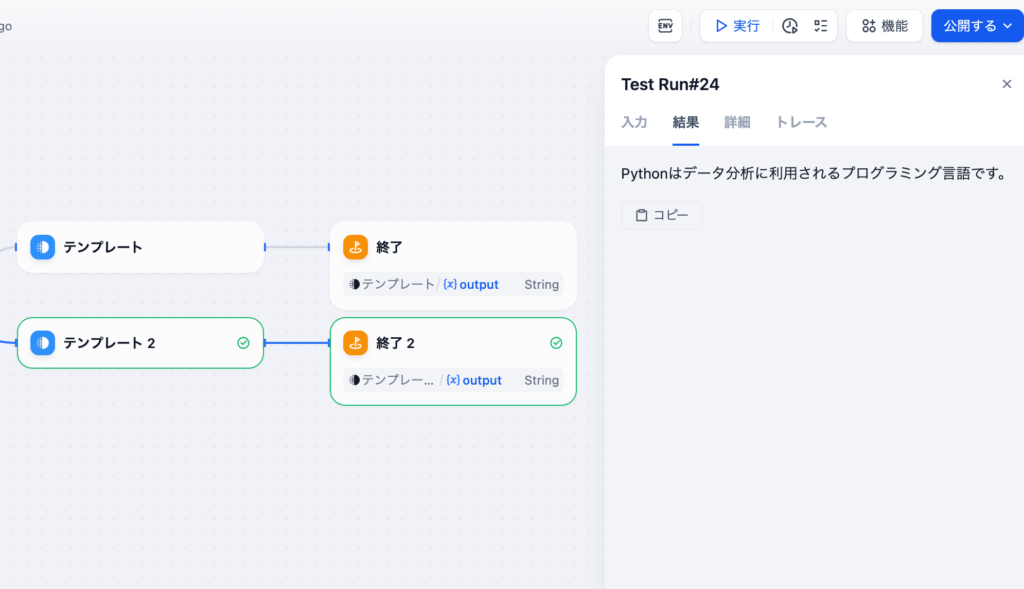
設定後に”実行”でPythonを選択するとテンプレートで設定した文字列が表示されます。
テンプレート内での分岐
テンプレート内ではJinja2というPythonで使われるテンプレートエンジンを利用して分岐を行うことができます。テンプレートで分岐を行うのでIF/ELSEノードを削除することができます。
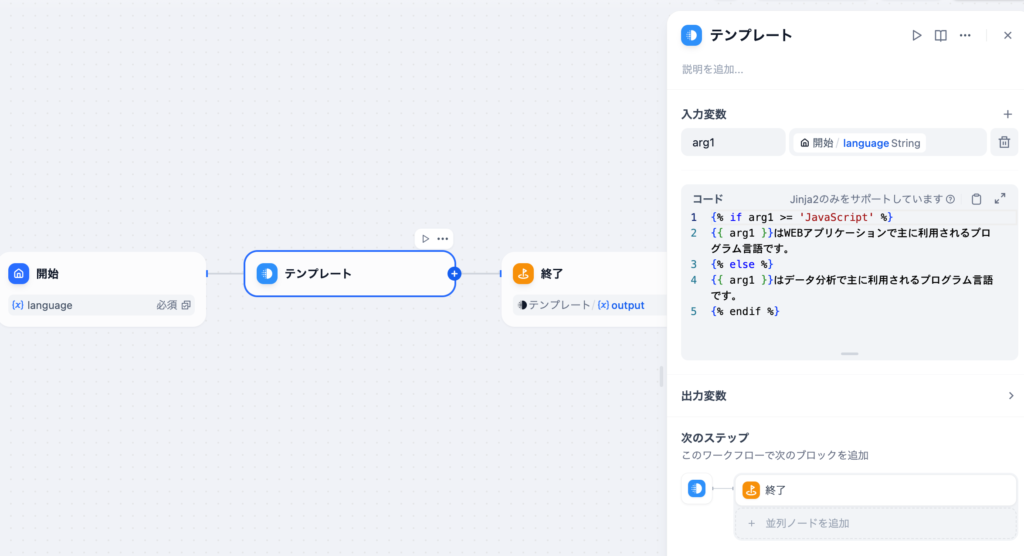
テンプレートに分岐を設定することでフローはシンプルになり、実行結果は変わりません。
質問分類器
質問分類器はLLM(大規模言語モデル)を利用して入力変数の値を基にフローを分岐させることができます。分類には、質問分類器で設定したクラス(分類)とそのクラスに設定された値が使用されます。
例えば、入力変数にプログラムのコードを渡しそのコードがどのプログラミング言語で記述されているかを識別して、フローを分岐させることが可能です。ただし、LLMによる分類結果を基に分岐を行うため、分類の正確性は必ずしも保証されない点に注意が必要です。
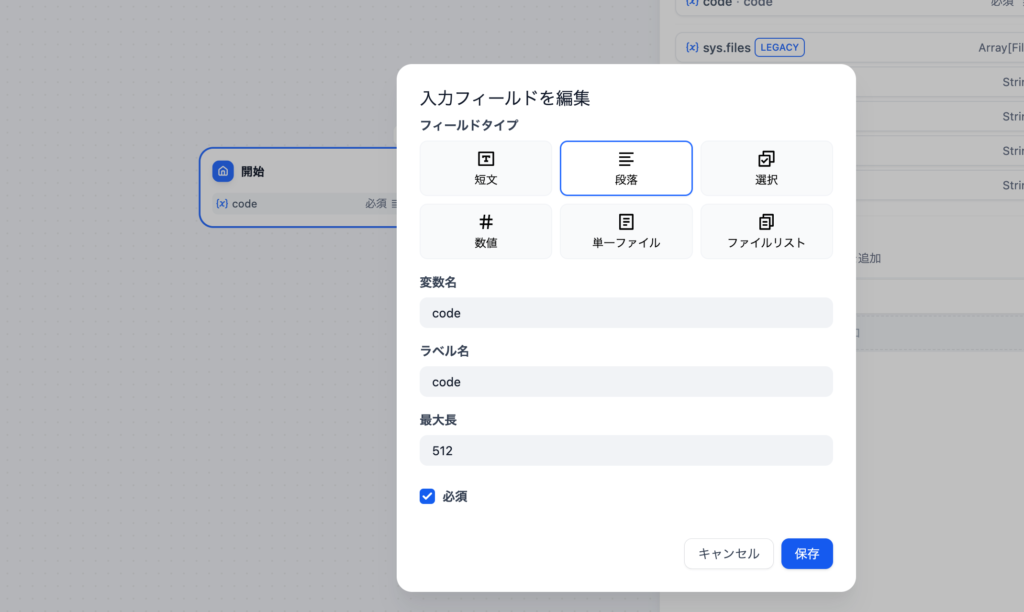
開始ノードではプログラムのコードが記述できるように段落を選択して変数名にはcodeを設定します。
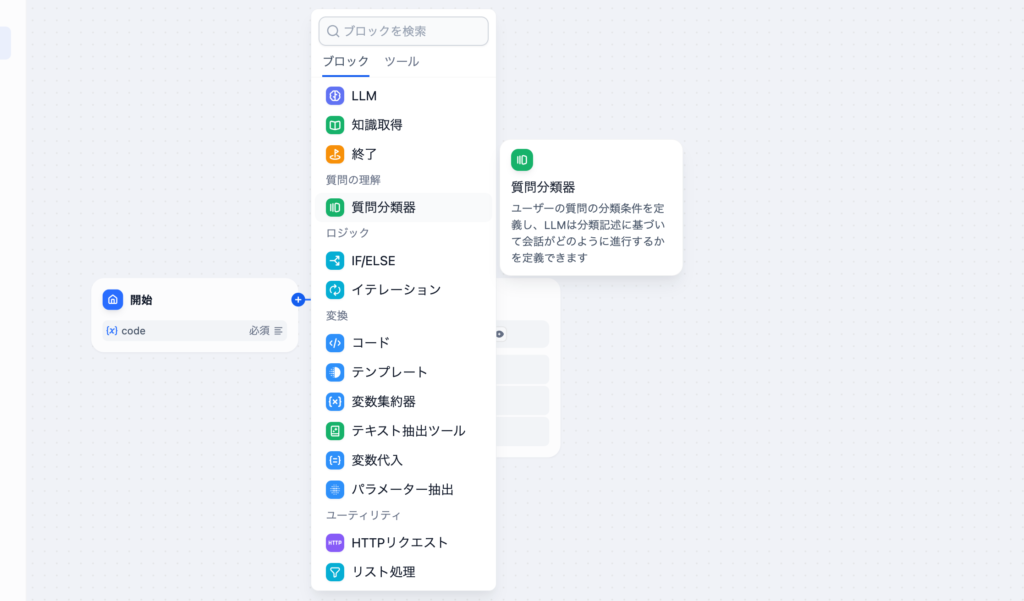
次に開始ノードの”+”ボタンをクリックして質問の理解のカテゴリーから”質問分類器”ブロックを選択します。
質問分類器ではモデル、入力変数、クラス(分類)を設定します。処理後の出力変数はclass_nameです。
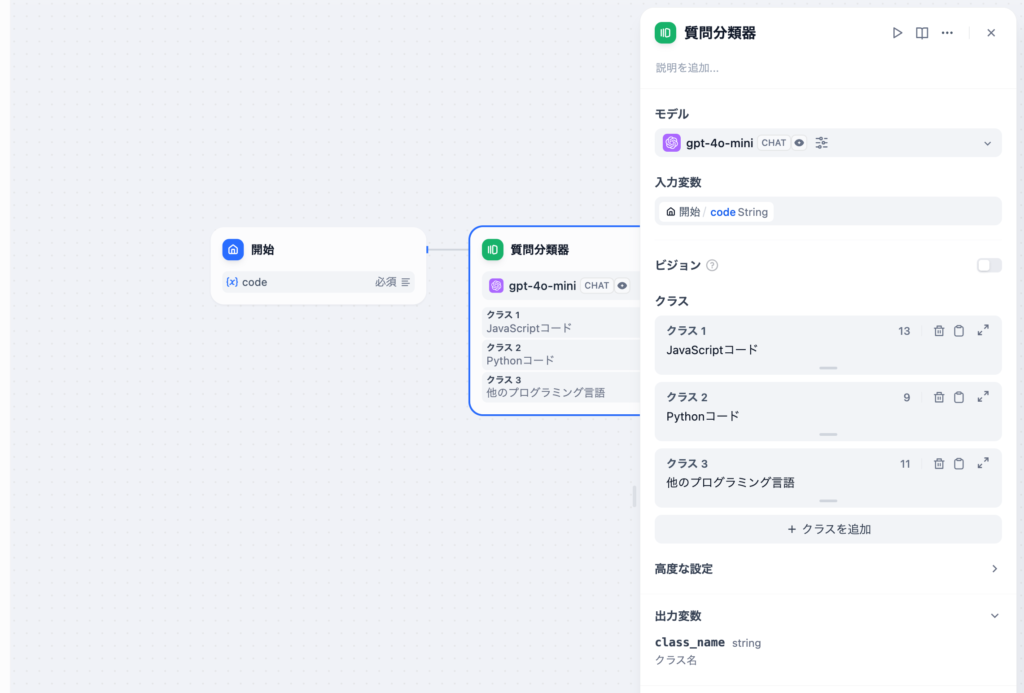
高度の設定でプロンプトを追加することは可能ですが、クラス(分類)に設定した値を利用してLLMが分類を行うのでプロンプトの設定を行う必要はありません。
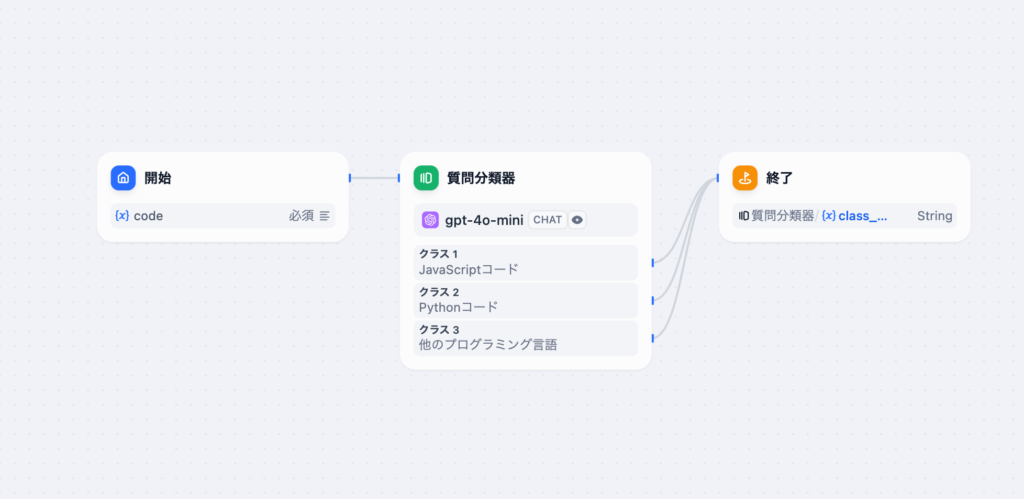
質問分類器の後は通常は分類によってフローが変わりますがここでは終了ノードを利用して分類が正しく行われるのかclass_nameの確認を行います。class_nameは質問分類器の出力変数です。
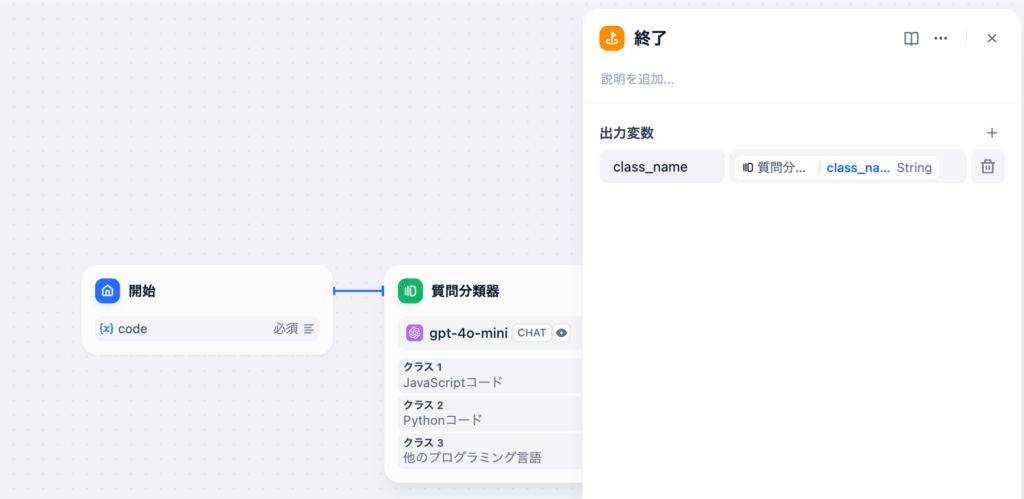
すべての分類から一つの終了ノードを繋ぎます。
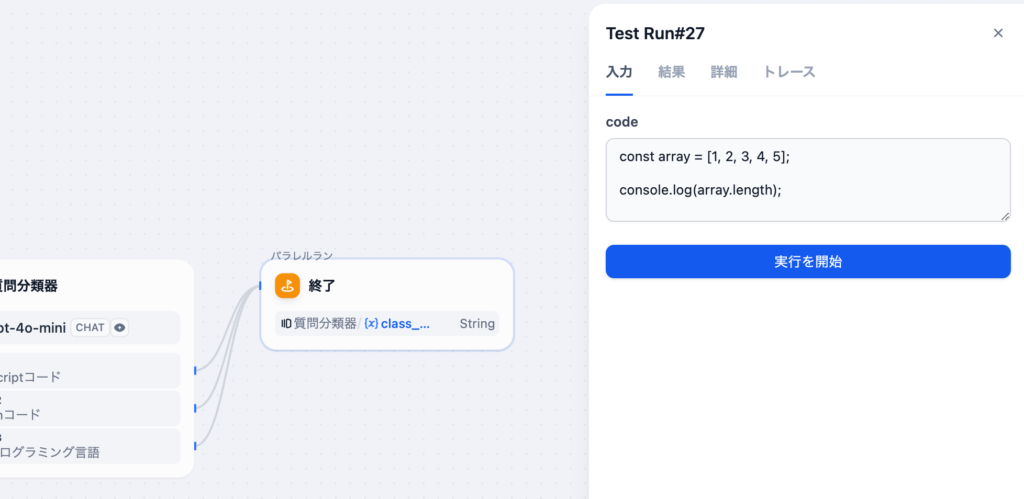
入力フィールドのcodeにJavaScriptのコードを記述して実行します。
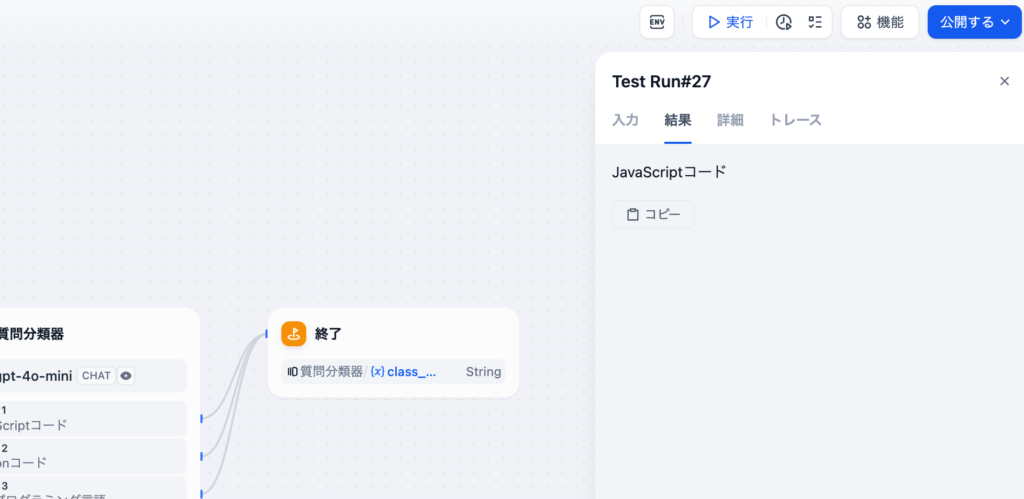
結果にはclass_nameが表示されるので質問分類器で設定したクラス(分類)名が表示されます。正しく動作していることがわかります。
実際に質問分類器ではどのようなプロンプトをLLMに送信しているかはトレースのデータ処理から確認することができます。
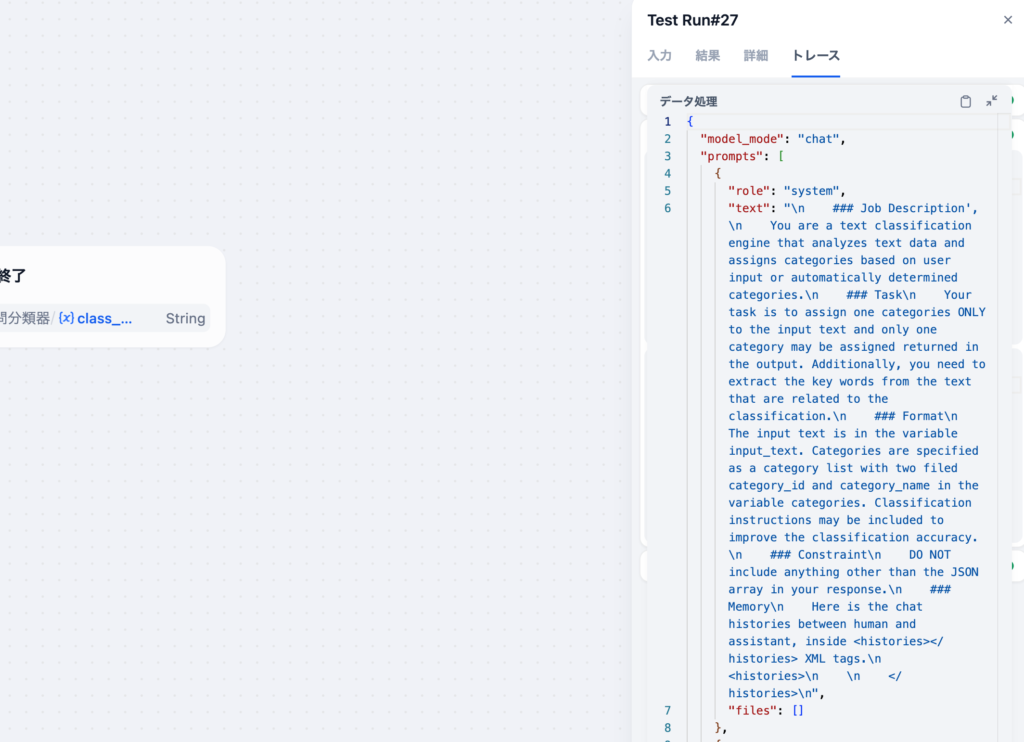
質問分類器のプロンプトの中では分類の例として2つの例を渡しています。
一つ目の例は入力テキスト”I recently had a great experience with your company. The service was prompt and the staff was very friendly.”と4つの分類(Customer Service、Satisfaction, Sales, Product)を与えて、該当する分類はCustomer Serviceだと伝えています。
もう一つの例は入力テキスト”bad service, slow to bring the food”と3つの分類(Food Quality, Experience, Price)を与えて、該当する分類は”Experience”だと伝えています。
質問分類器は最初は難しく感じるかもしれませんが内容を理解すれば非常にシンプルであることがわかります。
今後その他のブロックについて追記する予定です。