Python Pandas Excelデータで行・列結合(複数列)

Pythonのデータ解析のライブラリであるpandasを利用してExcelから読み出したデータを結合する方法を確認します。
通常データ解析を行おうと思った場合に社内にある複数のファイルを使ったりシート毎に登録されたデータを結合する必要が出てくる場合があります。結合が必要になった場合に対応できるようpandasのconcatとmergeを利用した結合方法を理解しておきましょう。
目次
データを結合する(concat)
pandasのconcatメソッドを使えば、2つのファイルに分かれた2つのテーブルを結合することができます。結合は単純な処理で2019年のテーブルの下に2018年のテーブルを追加するといったものです。

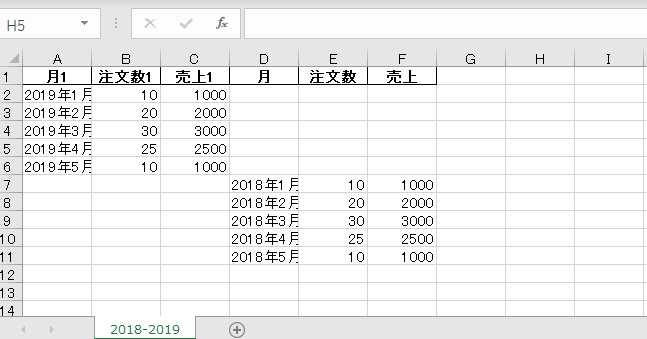
結合のために以下の2つのファイルを用意しました。一つは2019年の月ごとの注文数と売上です。もう一つは2018年の月ごとの注文数と売上です。
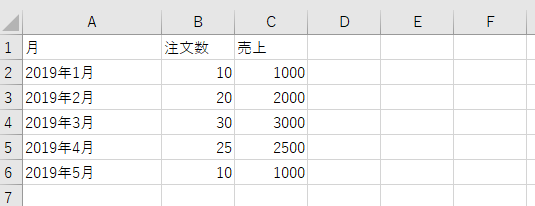
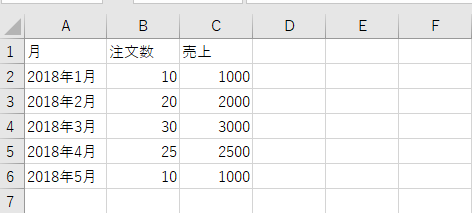
pandasでのExcelデータの読み込みについては下記を参考にしてください。
read_excelメソッドでファイルを読み込みconcatメソッドで2つのEXCELから読み込んだデータフレームを指定して結合しています。
import pandas as pd
df1 = pd.read_excel('2019年売上.xlsx')
df2 = pd.read_excel('2018年売上.xlsx')
df_concat = pd.concat([df1,df2])
print(df_concat)
実行すると結合したテーブルを取得することができます。
$ py test.py
月 注文数 売上
0 2018年1月 10 1000
1 2018年2月 20 2000
2 2018年3月 30 3000
3 2018年4月 25 2500
4 2018年5月 10 1000
0 2019年1月 10 1000
1 2019年2月 20 2000
2 2019年3月 30 3000
3 2019年4月 25 2500
4 2019年5月 10 1000
結合したテーブルをprint関数で表示させましたが、結合したデータを再度Excelで見たり処理を行いたいという要望も多いと思いますので、結合したデータをファイルに保存します。保存にはto_excelメソッドを使用します。
import pandas as pd
df1 = pd.read_excel('2019年売上.xlsx')
df2 = pd.read_excel('2018年売上.xlsx')
df_concat = pd.concat([df1,df2])
df_concat.to_excel('2019-2018年売上.xlsx',sheet_name="2018-2019")
下記が実行後作成したExcelファイルを開いた図です。結合したテーブルを書き出すことができましたが、A列に各テーブルのindexが表示されています。indexは通常必要ないので削除する方法を確認しておきます。
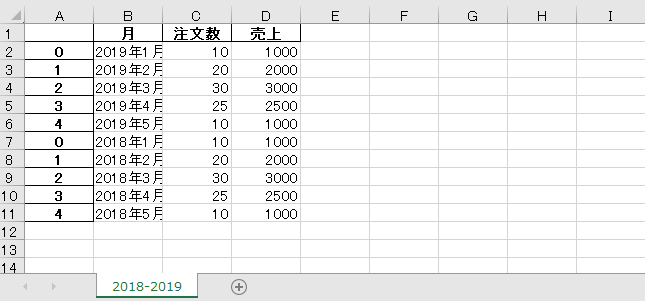
表示されているindexを結合データを保存するEXCELに書き込まないためにはindexオプションを設定をindex=Falseと設定します。
df_concat.to_excel('2019-2018年売上.xlsx',sheet_name="2018-2019",index=False)
index=Falseを設定するとindexの情報のEXCELデータへの書き込みがなくなり、期待したファイルを作成することができます。
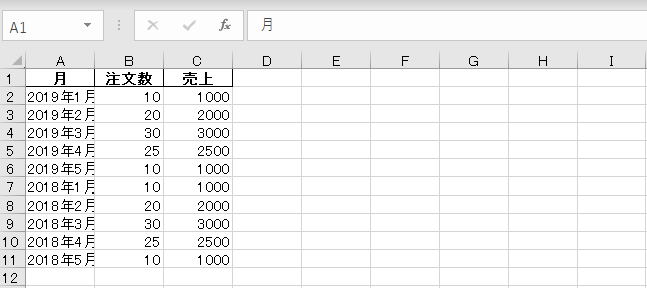
[commen]開いた時のフォントが異なるので見栄えが異なりますがフォントを変更すれば使用したファイルと同じように見えます。[/comment]
今回は列名が月、注文数、売上とどちらのファイルでも一致していましたが、もし一致していない場合は、concatでsort=Falseを設定する必要があります。実行結果は下記のようになります。
df_concat = pd.concat([df1,df2],sort=False)
データを結合する(merge)
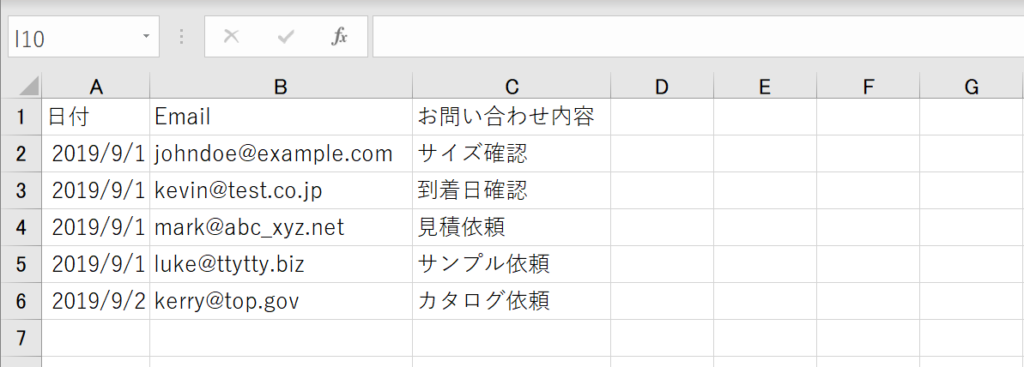
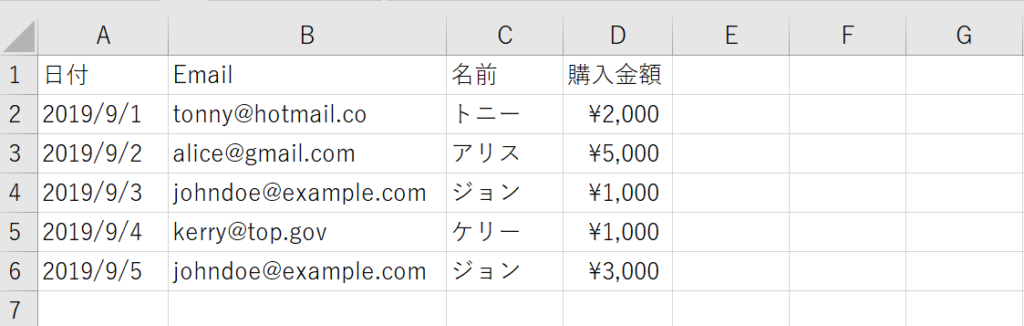
concatは単純に2つのテーブルを結合していましたが、今度は2つのテーブルに共通する列を元に結合を行います。その場合はconcatではなくmergeを利用します。一つはお問い合わせ一覧で日付、Email、お問い合わせの3つの列から構成されています。もう一つは注文一覧で日付、Email、名前、購入金額の4つの列で構成されています。Emailの共通の列を使って結合を行います。
2つのテーブルは下記の通りです。
Inner joinによる結合
Inner Joinではどちらのテーブルにも含まれているEmailアドレスの行だけ取り出すことができます。
import pandas as pd
df1 = pd.read_excel('お問い合わせ一覧.xlsx')
df2 = pd.read_excel('注文一覧.xlsx')
df_inner_join = pd.merge(df1,df2,on='Email',how='inner')
print(df_inner_join)
mergeメソッドではdf1とdf2のデータフレームを指定し、onには結合するためのkeyになるEmail、howは結合の方法であるinnerを指定しています。
実行するとEmailがどちらの表にも存在する3行の情報が表示されます。johedoeが2回表示されているのはお問い合わせを2回行っているためです。
$ py test.py
日付_x Email お問い合わせ内容 日付_y 名前 購入金額
0 2019-09-01 johndoe@example.com サイズ確認 2019/9/3 ジョン 1000
1 2019-09-01 johndoe@example.com サイズ確認 2019/9/5 ジョン 3000
2 2019-09-02 kerry@top.gov カタログ依頼 2019/9/4 ケリー 1000
どちらもテーブルにも存在した日付列は日付_xと日付_yとして表示されます。
Outer Joinによる結合
Outer JoinではすべてのEmailの行が表示されますが、どちらの表にも存在する行については1つの行として表示されます。
inner joinとのプログラム上での違いはhowをouterに設定する箇所のみです。
import pandas as pd
df1 = pd.read_excel('お問い合わせ一覧.xlsx')
df2 = pd.read_excel('注文一覧.xlsx')
df_outer_join = pd.merge(df1,df2,on='Email',how='outer')
print(df_outer_join)
実行すると8行が表示されます。Emailがどちらにもなかった行については各列にNaNが入っています。NaNはNo a Numberの略で値がないことを意味しています。お問い合わせ一覧のみにあったEmailの行は注文一覧の列に関して値がないのでNanとなり、注文一覧のみにあったEmailの行はお問い合わせ一覧の列に関しては値がないのでNanとなります。
$ py test.py
日付_x Email お問い合わせ内容 日付_y 名前 購入金額
0 2019-09-01 johndoe@example.com サイズ確認 2019/9/3 ジョン 1000.0
1 2019-09-01 johndoe@example.com サイズ確認 2019/9/5 ジョン 3000.0
2 2019-09-01 kevin@test.co.jp 到着日確認 NaN NaN NaN
3 2019-09-01 mark@abc_xyz.net 見積依頼 NaN NaN NaN
4 2019-09-01 luke@ttytty.biz サンプル依頼 NaN NaN NaN
5 2019-09-02 kerry@top.gov カタログ依頼 2019/9/4 ケリー 1000.0
6 NaT tonny@hotmail.co NaN 2019/9/1 トニー 2000.0
7 NaT alice@gmail.com NaN 2019/9/2 アリス 5000.0
Left Joinによる結合
Left Joinではmergeメソッドで先に指定したデータフレームのEmailがすべて表示され、後に指定されたデータフレームについては先に指定したデータフレームと一致したEmailがある場合のみ表示されます。
今回は先にお問い合わせ一覧のデータフレームを指定するのでお問い合わせ一覧のEmailの行はすべて表示されます。
import pandas as pd
df1 = pd.read_excel('お問い合わせ一覧.xlsx')
df2 = pd.read_excel('注文一覧.xlsx')
df_left_join = pd.merge(df1,df2,on='Email',how='left')
print(df_left_join)
実行するとお問い合わせ一覧のEmailの行はすべて表示され、注文一覧のEmailの行についてはお問い合わせ一覧にあるもののみ表示されています。
$ py test.py
日付_x Email お問い合わせ内容 日付_y 名前 購入金額
0 2019-09-01 johndoe@example.com サイズ確認 2019/9/3 ジョン 1000.0
1 2019-09-01 johndoe@example.com サイズ確認 2019/9/5 ジョン 3000.0
2 2019-09-01 kevin@test.co.jp 到着日確認 NaN NaN NaN
3 2019-09-01 mark@abc_xyz.net 見積依頼 NaN NaN NaN
4 2019-09-01 luke@ttytty.biz サンプル依頼 NaN NaN NaN
5 2019-09-02 kerry@top.gov カタログ依頼 2019/9/4 ケリー 1000.0
Right Joinによる結合
Right JoinはLeft Joinの逆で、mergeの後に指定したデータフレームのEmailはすべて表示され、先に指定されたデータフレームについては後に指定したデータフレームと一致したEmailがある場合のみ表示されます。
後に指定した注文一覧のEmailの行はすべて表示されます。howをrightに指定します。
import pandas as pd
df1 = pd.read_excel('お問い合わせ一覧.xlsx')
df2 = pd.read_excel('注文一覧.xlsx')
df_right_join = pd.merge(df1,df2,on='Email',how='right'')
print(df_right_join)
実行すると注文一覧のEmailの行はすべて表示され、お問い合わせのEmailの行については注文一覧にあるもののみ表示されています。
$ py test.py
日付_x Email お問い合わせ内容 日付_y 名前 購入金額
0 2019-09-01 johndoe@example.com サイズ確認 2019/9/3 ジョン 1000
1 2019-09-01 johndoe@example.com サイズ確認 2019/9/5 ジョン 3000
2 2019-09-02 kerry@top.gov カタログ依頼 2019/9/4 ケリー 1000
3 NaT tonny@hotmail.co NaN 2019/9/1 トニー 2000
4 NaT alice@gmail.com NaN 2019/9/2 アリス 5000
複数列の結合
これまではテーブルの1つの列の結合を行ってきましたが、複数の行を使って結合を行いたい場合は下記のように配列を利用して行うことができます。下記の処理だと品番と色と数量が一致する行と一致しない行を確認することができます。
df_merge_file = pd.merge(df1,df2,on=["品番","色","数量"],how="outer",indicator=True)
データの結合はデータ分析をする際に頻繁に利用される機能です、特にmergetの列結合についてはそれぞれ(inner, outer, left, right)の処理をしっかりと理解してさまざまな条件で適切な処理方法を選択できるようにしておいてください。