【Python Pandas】2つのEXCELファイルのデータで同じ値を持っていない行を抽出

Python Pandasを使って、2つのEXCELファイルに保存されたテーブルデータを読み出し、テーブルデータのある列を比較して同じ値を持っていない行を抽出する方法を確認します。
EXCELの機能を使っても可能ですが、Pythonのpandasの理解を深めることとPythonを業務の効率化に活用したいという人のヒントになればと本文書を公開しています。
目次
2つのEXCELファイルについて
下記のように各EXCELファイルには商品の発送に関するデータが保存されています。1つは商品名と発送予定日の列で構成されたテーブルでもう一つは商品名と発送日の列で構成されたテーブルです。
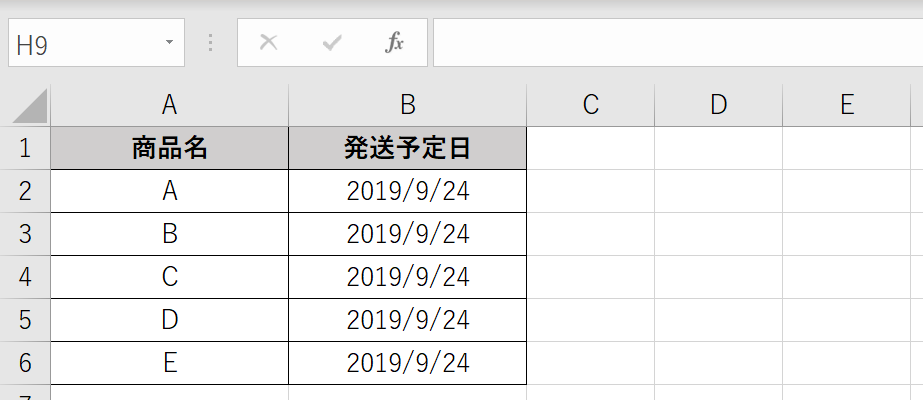
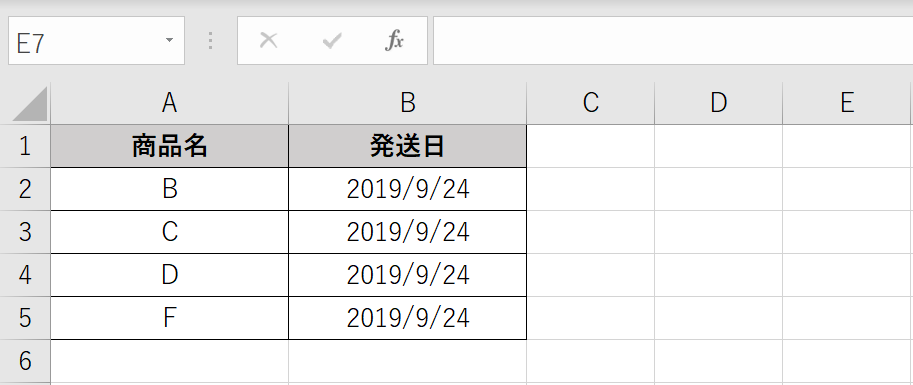
9/24に発送予定されていた商品がすべて予定通りに発送されるのかを調べることを目的にコードを作成していきます。

実行コード
pandas.mergeのindicatorオプションを利用
下記が2つのテーブルの商品列で同じ値を持っていない行を抽出するコードです。pandasでEXCELファイルを読み込み、値の比較を行いたい商品名の列を使ってmergeしているだけですが、ポイントはindicator=Trueに設定していることです。
import pandas as pd
df_a = pd.read_excel('a.xlsx')
df_b = pd.read_excel('b.xlsx')
df_a_b = pd.merge(df_a,df_b,on="商品名",how="outer",indicator=True)
print(df_a_b)
pandasのmergeについては以下の文書を参考にしてください。

実行すると下記の結果が得られます。indicator=Trueを設定することで右側に新たな列(_merge)が表示されます。
left_onlyはpd.mergeで先に指定したa.xlsxのテーブルだけが持っている商品名の行を表し、right_onlyはb.xlsxのテーブルだけが持っている商品名の行を表しています。bothはどちらのテーブルも持っている行を表しています。
商品名 発送予定日 発送日 _merge
0 A 2019-09-24 NaT left_only
1 B 2019-09-24 2019-09-24 both
2 C 2019-09-24 2019-09-24 both
3 D 2019-09-24 2019-09-24 both
4 E 2019-09-24 NaT left_only
5 F NaT 2019-09-24 right_only
発送されなかった商品を抽出
発送を予定していたのに発送されなかった商品だけ以下のコードで抽出します。発送予定日が記載されているa.xlsx側にある行だけを抽出しています。
import pandas as pd
df_a = pd.read_excel('a.xlsx')
df_b = pd.read_excel('b.xlsx')
df_a_b = pd.merge(df_a,df_b,on="商品名",how="outer",indicator=True)
print(df_a_b[df_a_b["_merge"] == 'left_only'])
実行すると下記のような結果が得られます。
AとEが実際には発送されていないことがわかります。a.xlsxのみにある行だけを抽出することができました。
商品名 発送予定日 発送日 _merge
0 A 2019-09-24 NaT left_only
4 E 2019-09-24 NaT left_only
条件を使った抽出
実行したコードの中身をもう少し見ていきます。下記は条件式を表しており、_merge列の中でleft_onlyを持っている行にはTrueが設定され、持っていない場合にはFalseが設定されます。
df_a_b["_merge"] == 'left_only'
この部分だけ実行するとTrue, Falseのみを含んだ情報が表示されます。
0 True
1 False
2 False
3 False
4 True
5 False
Name: _merge, dtype: bool
このTrue, Falseの値の入ったデータを利用して、Trueの行のみ表示させているのか下記のコードになります。
df_a_b[df_a_b["_merge"] == 'left_only']
発送を予定していない商品の抽出
_merge列にはleft_onlyだけではなくright_onlyも表示されているので、発送を予定していない商品についても抽出することができます。
import pandas as pd
df_a = pd.read_excel('a.xlsx')
df_b = pd.read_excel('b.xlsx')
df_a_b = pd.merge(df_a,df_b,on="商品名",how="outer",indicator=True)
print(df_a_b[df_a_b["_merge"] == 'right_only'])
実行結果で商品Fが発送予定になかったのに発送されていることがわかります。
商品名 発送予定日 発送日 _merge
5 F NaT 2019-09-24 right_only
2つのEXCELファイルがあり比較したい列を選択して実行すると一方のEXCELのみ存在するデータ、もう一方のEXCELに存在するデータを個別に短時間で見つけることができます。